[ODQA] 프로젝트 개요 및 EDA 기반 전략 수립
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
프로젝트의 전반적인 개요와 EDA결과 및 수립 전략에 대해 정리한 글 입니다.
프로젝트 소개
부스트캠프 AI Tech 8기에서 첫번째로 진행한 팀프로젝트는 ODQA(Open-Domain Question Answering)이었습니다. Open-Domain Question Answering(ODQA)은 주어진 지문이 따로 존재하지 않고, 사전에 구축된 Knowledge Resource에서 질문에 답할 수 있는 문서를 찾아서 답변하는 문제입니다.
해당 프로젝트에서는 Wikipedia 코퍼스를 대상으로, 사용자의 질문에 대해 관련 문서를 검색(Retrieval) 하고 해당 문서에서 정확한 답변을 추출(Reading) 하는 ODQA 시스템을 구축하고 최적화를 진행하는 것이었습니다.
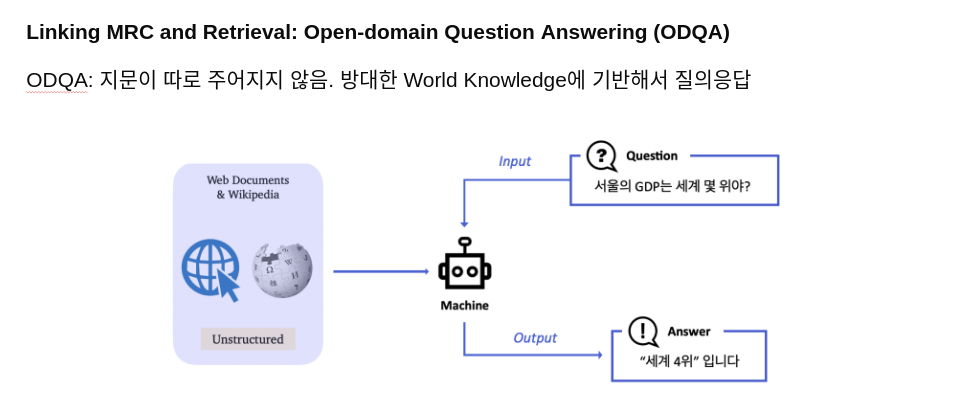
평가 기준은 Exact Match(EM) 과 F1 Score이며, EM 기준으로 리더보드 등수가 정해졌습니다.
프로젝트 진행을 위해 Tesla V100-SXM2-32GB 서버 3개가 개발환경으로 주어졌습니다.
EDA 분석 결과
제공된 데이터셋은 Train 3,952개, Validation 240개, Test 600개, Wikipedia Documents 60,613개이었습니다.
데이터셋 구조
# Train Dataset (3,952 samples + validation 240 samples)
{
"title": "문서 제목 (문맥 메타정보)",
"context": "질문에 대한 지문 (정답 포함)",
"question": "입력 질문",
"id": "sample 고유 ID",
"answers": {"text": [...], "answer_start": [...]},
"document_id": "원본 문서 식별용 ID"
}
# Test Dataset (600 samples) — question, id만 제공
# Wikipedia Documents (60,613 documents) — text, title, document_id 등
학습 데이터 확인
먼저 주어졌던 학습데이터가 적절한지 확인하기 위해 학습 데이터의 context가 Wikipedia에 모두 존재하는지 확인했습니다.
[Matching Results]
Exact matches: 3952 (100.0%)
No matches: 0 (0.0%)
기초 통계 분석
- context 길이 분포
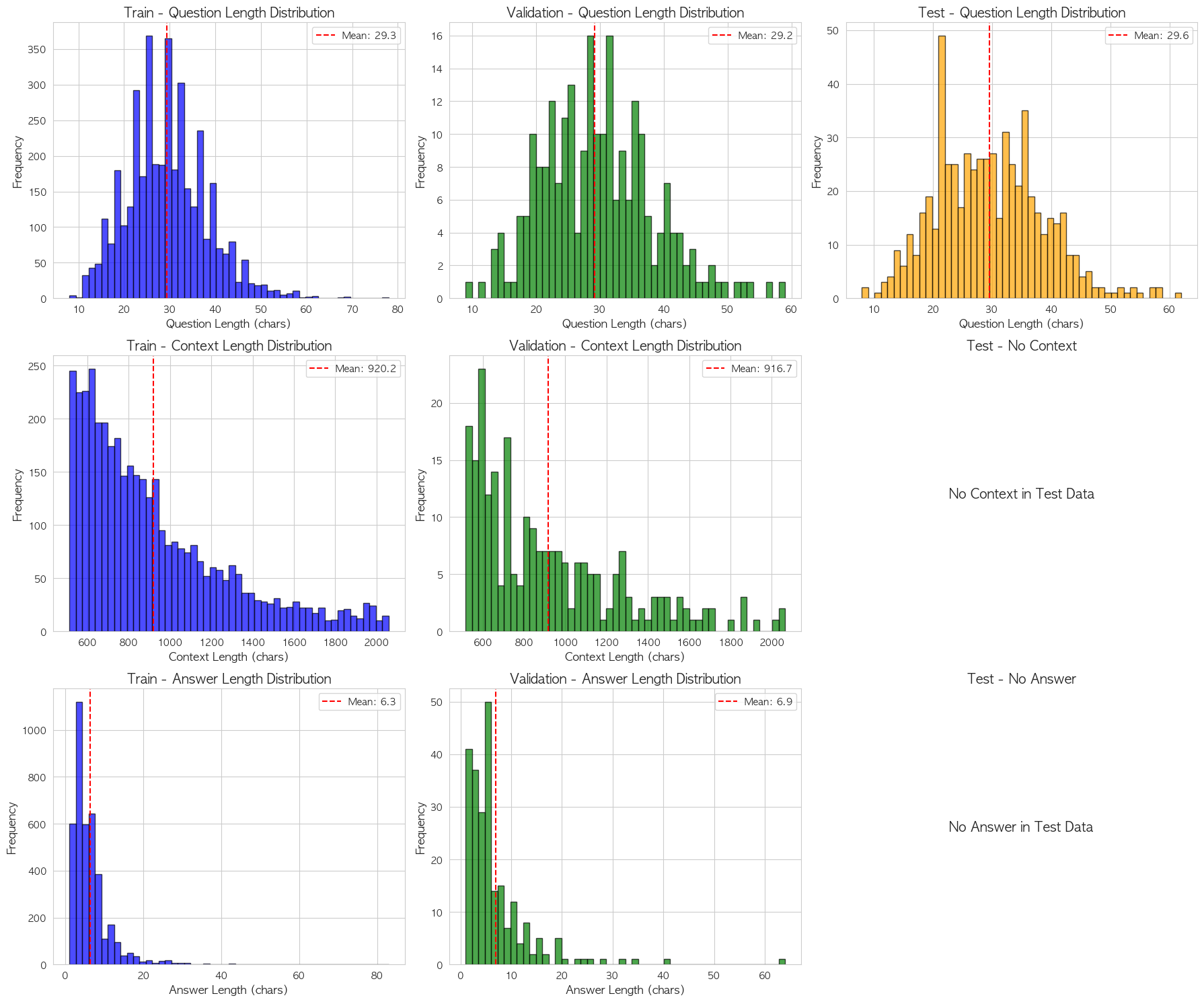
- 대부분의 context가 400~1,000자 구간에 분포하며, 2,000자에 육박하는 긴 지문도 상당수 존재했습니다.
- 질문 길이는 대부분 30~50자 내외로 짧고 편차가 크지 않음을 확인하였고, 질문의 길이가 10자 정도로 짧은 질문도 있음을 확인하였습니다.
- 정답은 대부분 짧은 단어나 구(phrase) 형태로, 길이가 매우 짧은 쪽에 편중되어있는 것을 확인하였습니다. 이는 Span Extraction 기반 QA 모델에 적합한 분포라고 볼 수 있습니다.
- Wikipedia 문서 도메인 분포
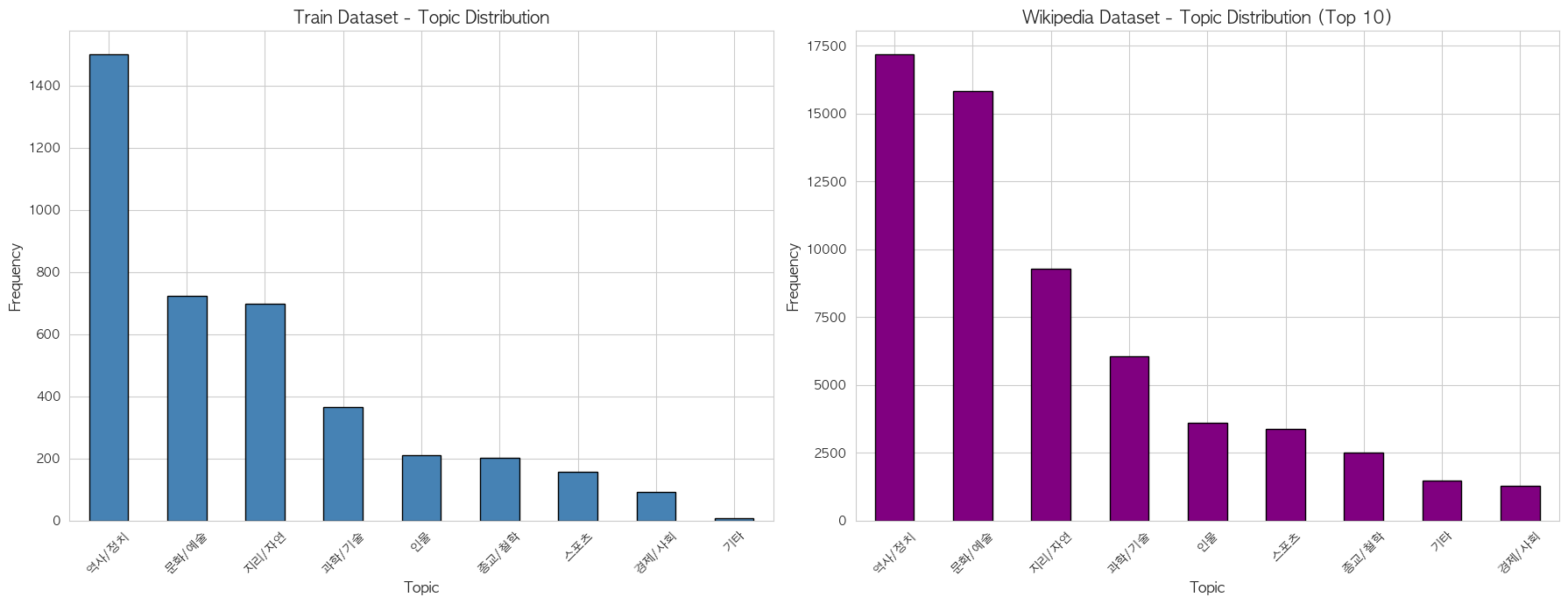

추가적으로 학습 데이터와 Wikipedia 문서의 도메인 분포도 분석했습니다.
- 학습 데이터와 Wikipedia 문서 모두 역사/정치 도메인이 가장 많은 비중을 차지하며, 문화/예술, 지리/자연이 그 뒤를 이었습니다.
- 전반적인 도메인 순위는 양쪽에서 유사하게 나타나, 학습 데이터가 Wikipedia의 도메인 분포를 어느 정도 반영하고 있는 것으로 판단됩니다.
- 정답 유형별 분포
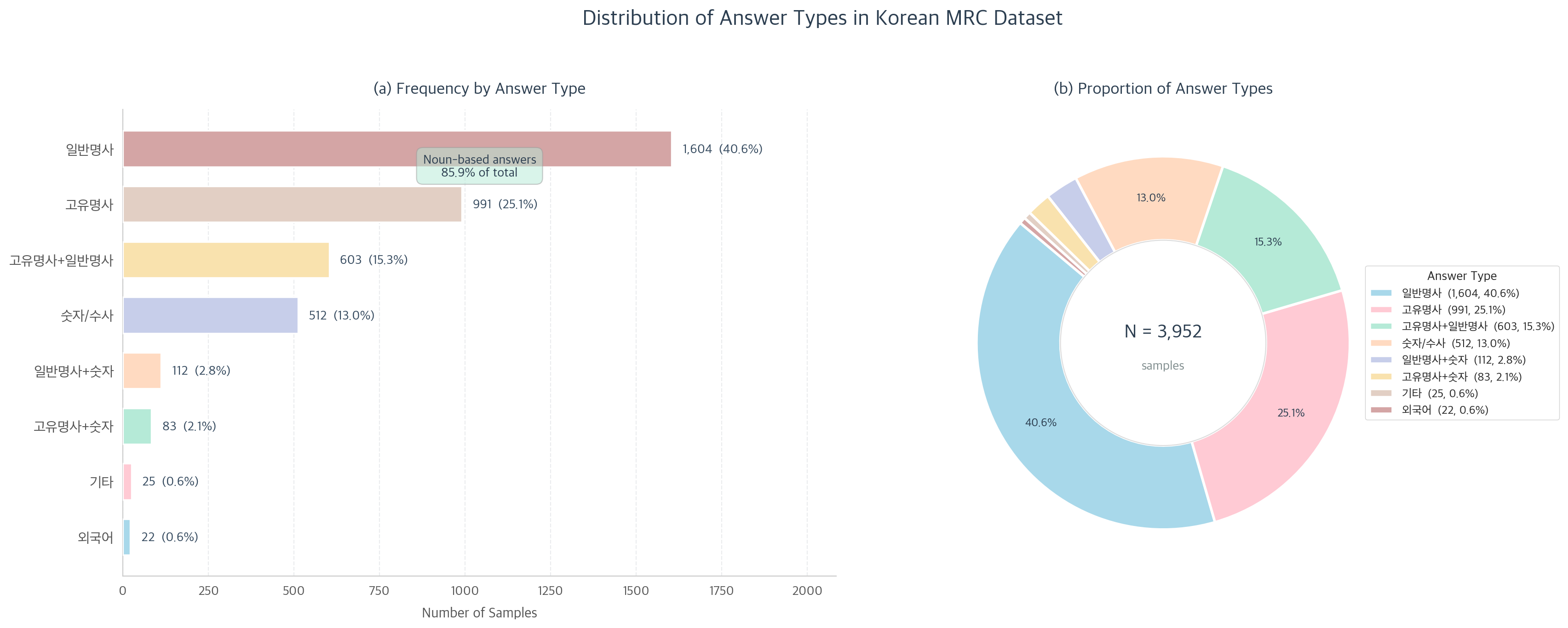
학습데이터의 정답의 유형별 분포를 분석하여, 답변이 어떤 형식으로 되어 있는지도 확인하였습니다.
- 일반명사(40.6%)와 고유명사(25.1%)가 가장 높은 비율을 차지했으며, 이 둘의 조합까지 포함하면 전체 정답의 85.9%가 명사 기반이었습니다.
- 숫자/수사 유형도 13.0%로 일정 비율을 차지했으며, 외국어나 기타 유형은 극소수였습니다.
- 정답 대부분이 명사 형태라는 점은, Span Extraction 기반 Reader가 명사구를 정확히 짚어내는 능력이 성능에 직결된다는 것을 의미합니다.
모델 입력에 영향을 줄 수 있는 요소 분석
기초 통계를 진행하고 제가 가장 관심을 가진 것은 Long Context 에서 오는 문제들이었습니다.
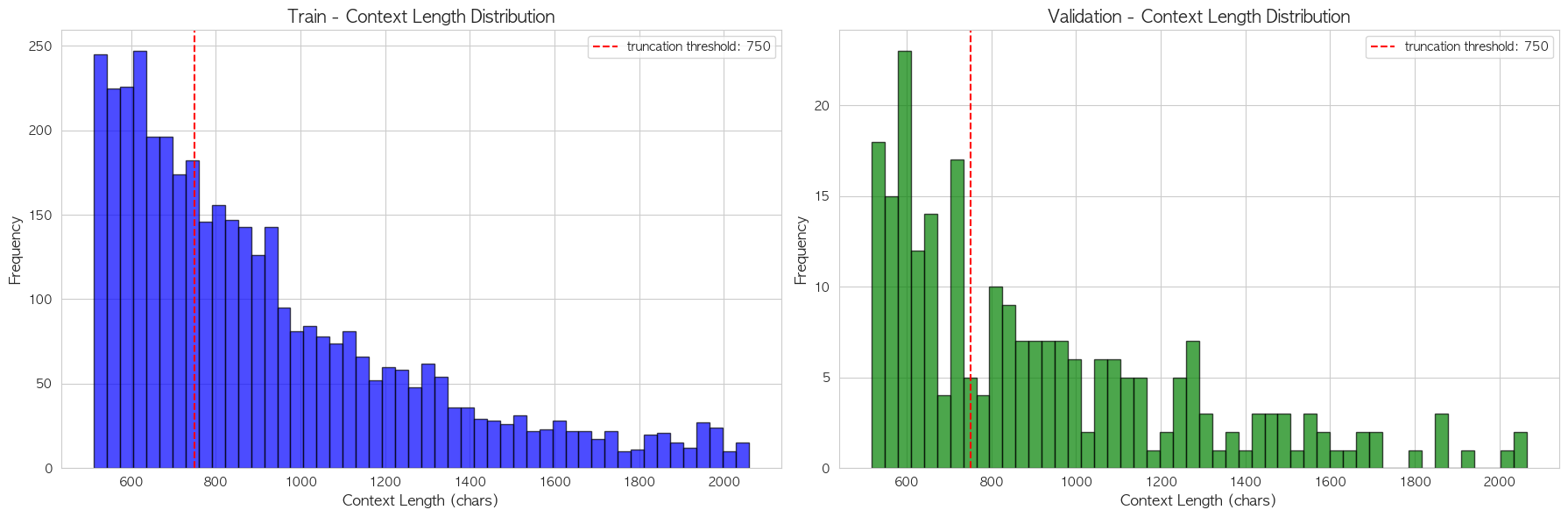
ModernBERT는 더 긴 context를 입력으로 받을 수 있기는 하지만, 일반적인 BERT 계열 모델은 최대 512 토큰까지만 입력으로 받을 수 있습니다. 모델이 입력 받을 수 있는 context 길이를 초과하면 truncation으로 인해 정답 정보가 손실될 수 있습니다. 따라서, 512토큰(약 750자)을 기준으로 context 길이 분포를 확인한 결과,
- 750자 이상: 2,321개 (58.7%)
- 750자 미만: 1,631개 (41.3%)
임을 확인하였습니다.
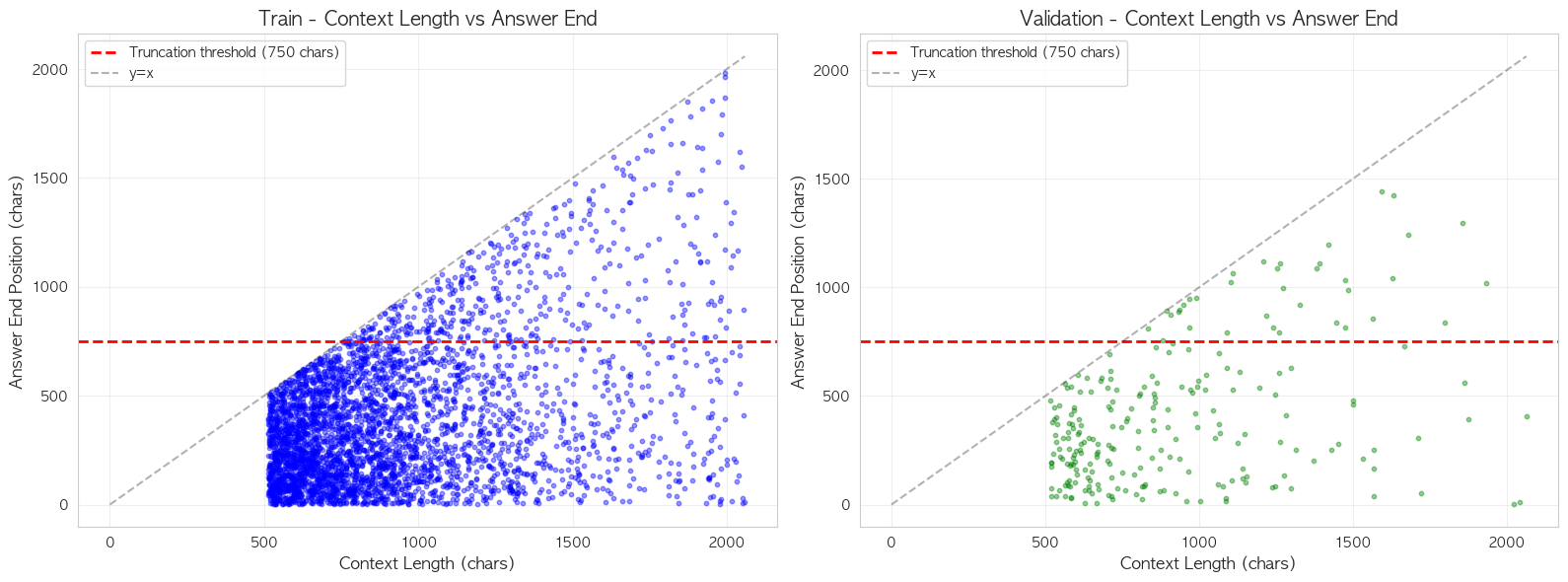
추가적으로, 실제 정답의 위치가 512토큰(약 750자) 이후에 위치해 정답 관련 컨텍스트가 잘리는 것을 확인했을 때,
- 정답이 truncation threshold 이후에 끝나는 경우: 439개 (11.1%)
Wikipedia 문서 길이 분포
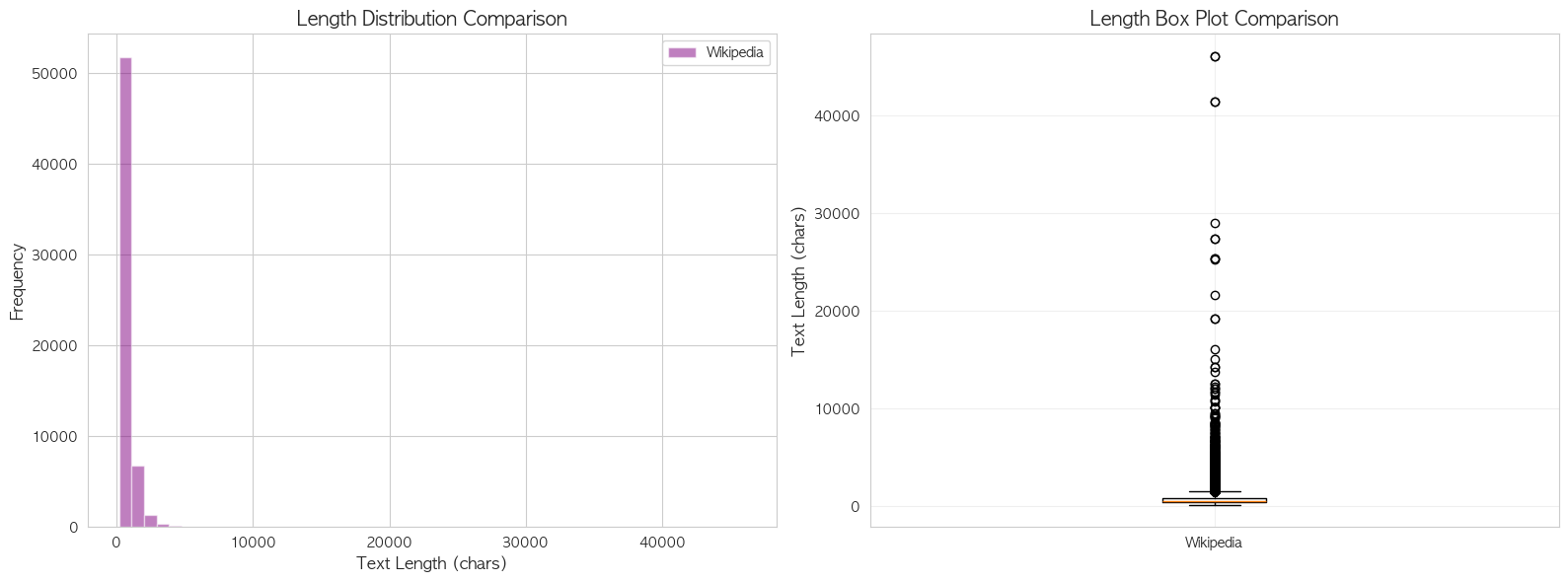
- 평균: 755자, 최대: 46,099자
- 문서의 길이가 비정상으로 긴 outlier 존재
- 추론 시에도 긴 문서가 입력될 가능성이 높음
을 확인하였습니다.
전략 수립
EDA 결과를 참고해서 제가 이번 프로젝트에 적용해보고 싶은 것들을 정하였습니다.
- Sliding Window + doc_stride 최적화로 Long Context 문제 해결 (Reader 파트)
- BM25 Tokenizer별 성능 비교를 통한 최적 설정 탐색 (Retrieval 파트)
- Retrieval (Sparse, Dense, Hybrid) 종류에 따른 성능 비교 및 적용 (Retrieval 파트)
마무리
이번 글에서는 ODQA 프로젝트의 개요와 EDA 결과를 바탕으로 문제를 정의하고, 이를 해결하기 위한 전략을 수립하는 과정을 정리하였습니다.
EDA 단계에서는 데이터의 신뢰성, 길이 분포, 도메인 분포, 정답 유형 분포 등을 확인하였고, 그중에서도 데이터 길이와 관련된 문제에 주목하기로 하였습니다.
분석 결과, 학습 데이터의 58.7%가 BERT 계열 모델의 입력 한계인 512토큰을 초과 했고, 정답이 truncation으로 잘리는 경우도 11.1% 에 달했습니다. 이는 단순히 입력을 잘라내는 것만으로는 성능 확보가 어렵다는 것을 의미했고, 긴 문서를 어떻게 다룰 것인지를 핵심 과제로 설정하였습니다.
한편, 모든 context가 한국어로 구성되어 있다는 점을 고려해 토크나이저 선택이 Retrieval 성능에 어떤 영향을 미치는지 함께 분석해보고자 하였습니다. 이를 위해, Sparse Retrieval 환경에서 토크나이저별 비교 실험을 진행하기로 하였습니다.
마지막으로, EDA를 통해 정답의 85.9%가 일반 명사 형태 로 이루어져 있다는 점도 확인할 수 있었습니다. 이를 바탕으로, 의미적 유사성보다는 질문과 문서간의 lexical overlap을 직접적으로 반영하는 Sparse Retrieval이 더 효과적일 것이라 생각했습니다. 따라서, Sparse, Dense, 그리고 이를 결합한 Hybrid 방식을 각각 적용해 성능을 비교하고, 어떤 조합이 데이터 특성에 가장 적합한지 확인하고자 하였습니다.