[ODQA] Reader 고도화 — Sliding Window & doc_stride 최적화
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
문제 정의
ModernBERT는 최대 8192토큰까지 입력할 수 있지만, 대부분의 BERT 계열 모델은 일반적으로 512토큰까지만 처리할 수 있습니다.
현재 학습 데이터는
- 학습 데이터의 58.7%가 512 토큰 한계를 초과
- 정답의 11.1%(439개)가 truncation 범위 밖에 위치
한다는 특징을 가지고 있습니다.
이러한 상황에서 단순하게 잘라버리는 truncation을 적용하면 이 데이터들의 정답 정보가 손실될 가능성이 높아 Reader 성능이 저하됩니다. 길이가 긴 context를 입력으로 받았을 때, 정보 손실 없이 모델에 학습하거나 추론할 수 있는 방법이 필요합니다.
Sliding Window
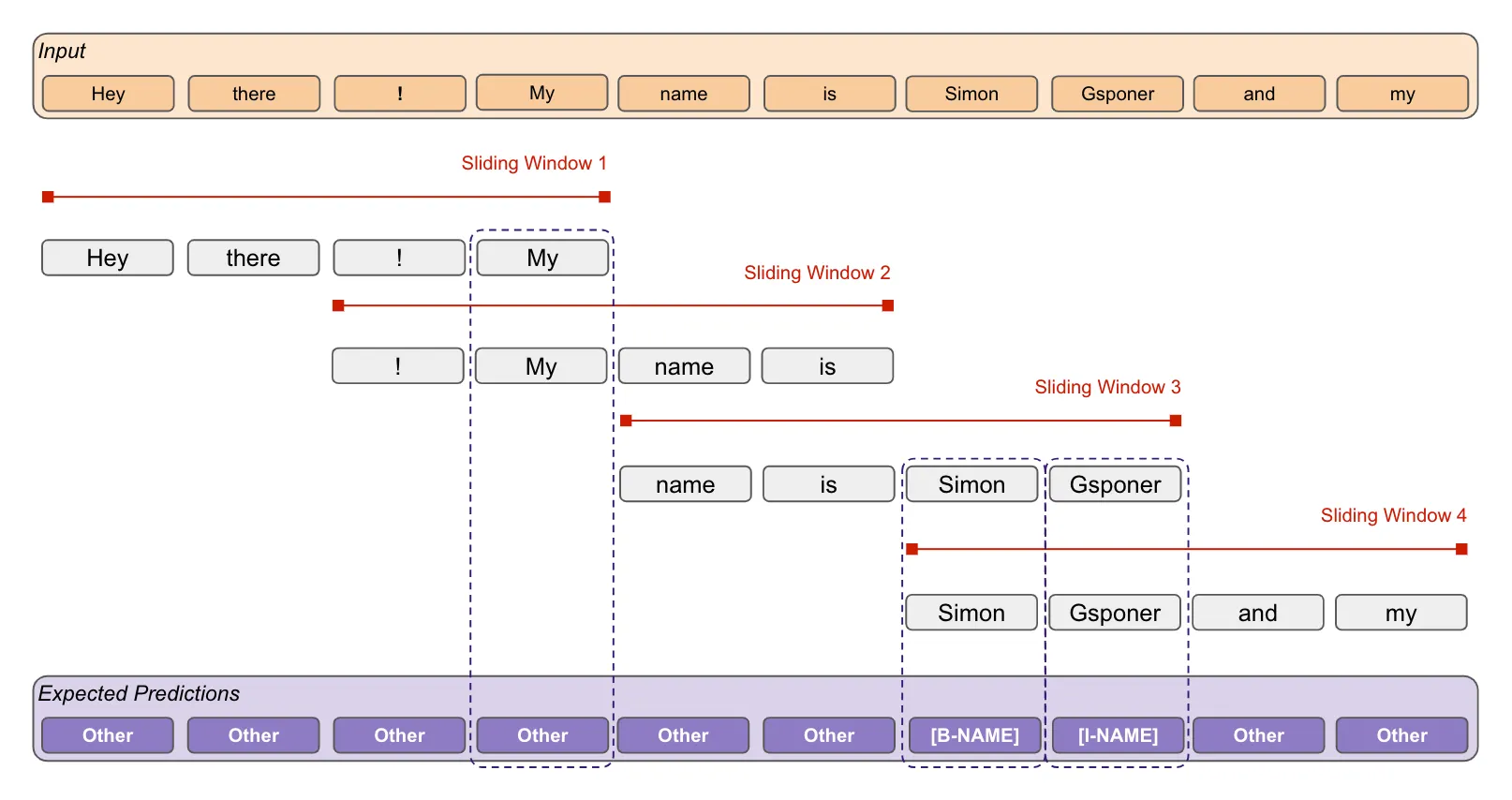
이를 해결하기 위해서 입력된 정보를 보는 window을 sliding 하면서 버리는 정보 없이 모든 context를 살펴보는 sliding window를 적용하기로 하였습니다.
Sliding window는 따로 구현하지 않고, HuggingFace Transformers에 이미 지원하고 있는 기능을 활용했습니다. 해당 기능에서는 두 개의 파라미터를 조정하여 sliding window의 전략을 조정할 수 있습니다.
max_seq_length- 한 window에 포함되는 문맥의 범위를 조절합니다.
- 값을 늘리면 한 번에 더 넓은 범위를 볼 수 있어 정답 포함 확률(recall)이 높아지지만, 스팬 탐색 공간이 확장되면서 정확한 선택(precision)이 저하될 수 있습니다.
doc_stride- 입력 길이를 늘리지 않고 window 간 overlap을 설정합니다.
- 적절한 overlap은 정답이 window 경계에 걸리는 문제를 완화하지만, 과도한 overlap은 유사한 후보 간 경쟁을 유발하여 precision을 떨어뜨릴 수 있습니다.
def preprocess(self, examples: Dict[str, List]) -> Dict[str, List]:
tokenized_examples = self.tokenizer(
],
examples[
self.context_column if self.pad_on_right else self.question_column
],
truncation="only_second" if self.pad_on_right else "only_first",
max_length=self.max_seq_length,
stride=self.doc_stride,
padding="max_length" if self.pad_to_max_length else False,
)
실험 설계 및 결과
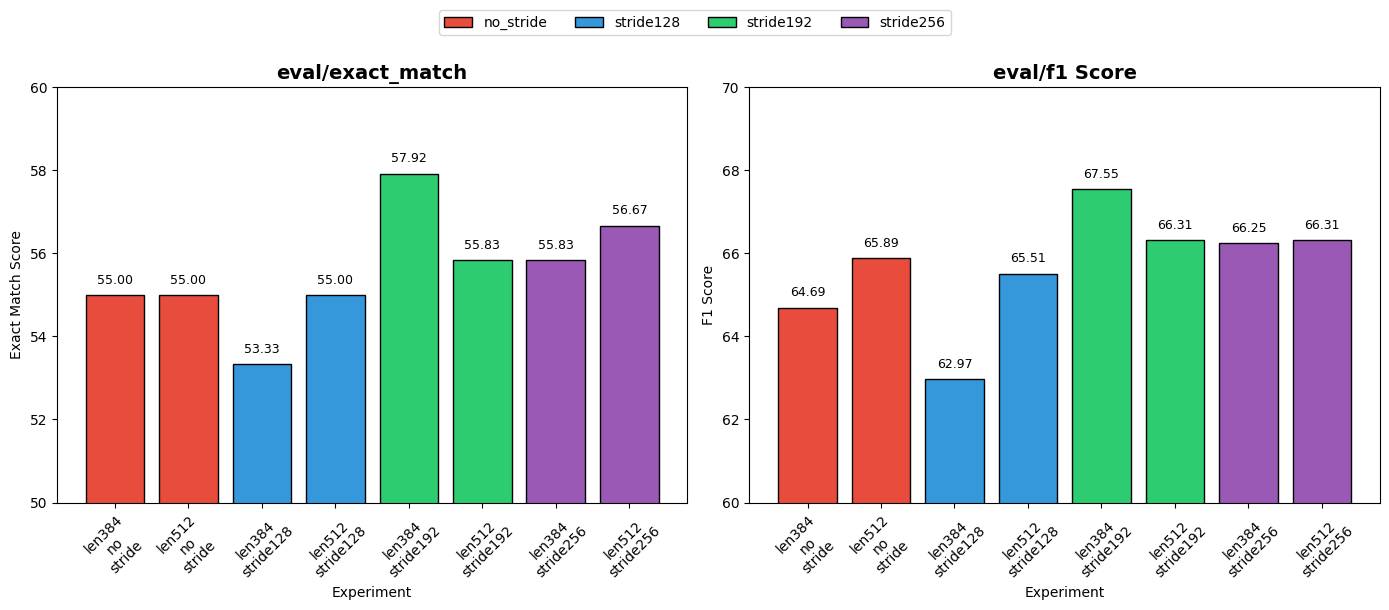
| 설정 | EM | F1 Score |
|---|---|---|
| len 384, no stride (baseline) | 55.00 | 64.69 |
| len 512, no stride | 55.00 | 65.89 |
| len 384, stride 128 | 53.33 | 62.97 |
| len 384, stride 192 | 57.92 | 67.55 |
| len 384, stride 256 | 55.83 | 66.25 |
| len 512, stride 128 | 55.00 | 65.51 |
| len 512, stride 192 | 55.83 | 66.31 |
| len 512, stride 256 | 56.67 | 66.31 |
다양한 max_seq_length와 doc_stride의 조합을 grid search로 실험했습니다.
최적 조합은 max_seq_length=384, doc_stride=192로, baseline 대비 EM +2.92%p, F1 +2.86%p 향상되었습니다.
결과 분석
적정 Overlap의 필요성
실험 결과에서 가장 흥미로운 점은 너무 많은 overlap(큰 stride)이나 적은 overlap(작은 stride)보다 적정한 overlap(stride 192) 값이 존재한다는 점이었습니다. 큰 stride를 적용해서 overlap이 많으면 정보 보존이 잘되어 성능은 좋지만 효율성이 떨어지는 것으로 알고 있었지만, 실험결과 overlap이 많다고 해서 꼭 성능이 좋은 것은 아니고, 들어오는 입력 데이터의 특성에 따라 달라질 수 있다는 것을 다시 한번 느낄 수 있었습니다.
Overlap이 과도하거나 부족한 경우에 따라 왜 성능에 영향을 주었는지를 고민해보았는데,
- Overlap이 과도한 경우 (stride 256)
- 정답 span을 포함하는 window 수가 지나치게 증가할 수 있습니다.
- 따라서, 여러 후보 window에서 비슷한 점수를 가진 답변 span들이 늘어나면서, 최종 선택 단계에서 오답 span이 선택될 가능성이 높아집니다.
- Overlap이 부족한 경우 (stride 128)
- 정답 span이 window의 경계에 위치할 확률이 증가합니다.
- 정답이 부분적으로 잘린 상태로 모델에 전달될 수 있어, start/end 위치 예측이 불안정해 성능 하락이 올 수 있습니다.
sliding window의 한계
Sliding Window로 Long Context 문제를 상당 부분 해결했지만, 고정 크기 윈도우를 일정 간격으로 나누어 처리하는 방식 자체가 가지는 한계가 있습니다.
- 맥락 불균형: 정답이 window의 경계(시작/끝)에 위치할 경우, 정답 앞뒤의 문맥이 비대칭적으로 제공됨
- Irrelevant 문맥 증가: 문서가 길어질수록 생성되는 윈도우가 증가하며, 정답 주변의 핵심 문맥 비율보다 불필요한 문맥 비율이 증가
- 후반부 정답 불이익: 리트리버가 반환하는 문서가 길고 정답이 후반부에 위치하는 경우, doc_stride로 생성된 초기 negative chunk들을 처리한 후 정답 chunk를 처리하게 되어 상대적으로 낮은 logit이 출력
마무리
이번 글에서는 Long Context 문제를 해결하기 위해 Sliding Window를 적용하고, max_seq_length와 doc_stride 조합을 실험하여 최적의 설정을 찾는 과정을 정리했습니다.
실험을 통해 단순히 overlap을 늘린다고 성능이 올라가는 것이 아니라, 데이터 특성에 맞는 적정 overlap이 존재한다는 것을 확인할 수 있었습니다. 최적 조합인 max_seq_length=384, doc_stride=192에서 baseline 대비 EM +2.92%p, F1 +2.86%p의 성능 향상 을 얻었습니다.
또한, 고정 크기 윈도우 방식 자체가 가지는 맥락 불균형, 불필요한 문맥 증가, 후반부 정답 불이익 등의 한계도 고민했으며, 이러한 한계들을 보완할 수 있는 방법에 대한 필요성을 느끼기도 하였습니다.