[ODQA] Answer-Aware Window (Two-stage Reader) 설계와 구현
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
Sliding Window의 구조적 한계
Sliding Window를 적용함으로써 EM 55.0 → 57.92의 성능향상 을 달성했지만, 고정 크기 윈도우를 일정 간격으로 나누는 방식 자체의 구조적 한계는 여전히 남아 있었습니다.
- 맥락 불균형 — 정답이 window 경계에 위치하면 앞뒤 맥락이 비대칭적으로 제공됨
- Irrelevant 문맥 증가 — 문서가 길수록 윈도우 수가 늘어나고, 정답 주변 핵심 문맥의 비율이 감소하면서 start/end 확률 분포가 희석됨
- Negative chunk 누적 — 정답이 후반부에 위치하면 앞선 negative chunk들을 거치면서 정답 chunk의 logit이 상대적으로 낮아짐
이러한 문제를 해결하기 위해, 정답이 있을 가능성이 높은 위치를 먼저 파악한 뒤, 그 주변만 다시 집중적으로 읽는 방식 을 적용하기로 하였습니다.
첫 번째 시도: 학습 전처리 단계에서 Answer-Aware Window
처음에는 학습 데이터의 전처리 단계에서 정답 중심으로 context를 잘라내고 재구성함으로써, 정답이 window에 의해 잘리는 상황 자체를 없애면 문제가 해결될 것이라고 생각했습니다. 이에 따라 다음과 같이 구현하였습니다.
# src/data/preprocessor.py
def _get_optimal_context_window(self, context, answer_text, answer_start):
"""답변 위치를 기반으로 최적의 context 윈도우를 계산"""
available_char = int((self.max_seq_length - 20) * 1.5) # 한글 1.5자 ≈ 1토큰 근사
before_buffer = int(available_char * self.answer_buffer_ratio)
after_buffer = available_char - before_buffer
window_start = max(0, answer_start - before_buffer)
window_end = min(len(context), answer_start + len(answer_text) + after_buffer)
optimal_context = context[window_start:window_end]
adjusted_answer_start = answer_start - window_start
return optimal_context, adjusted_answer_start
def prepare_train_features(self, examples):
if self.use_answer_aware_truncation:
for i in range(len(examples[self.context_column])):
answer = examples[self.answer_column][i]
if len(answer["answer_start"]) > 0:
optimal_context, adjusted_start = self._get_optimal_context_window(
examples[self.context_column][i],
answer["text"][0],
answer["answer_start"][0],
)
examples[self.context_column][i] = optimal_context
examples[self.answer_column][i]["answer_start"][0] = adjusted_start
# 이후 토큰화 진행...
학습 데이터에는 answer_start가 제공되므로, 이 값을 이용해 정답 context를 가져와서 앞뒤에 buffer(정답 주변의 context)를 추가하여 새로운 context window를 만드는 방식이었습니다.
문제 발견: Train-Test Mismatch
구현할 당시에는 인지하고 있지 못하다가, 구현 후 곧바로 근본적인 문제가 있다는 것을 알아차렸습니다. 문제를 해결하기 위한 아이디어와 방향성은 맞지만 구현을 잘못했었는데,
일차적으로 정답의 가능성이 있는 위치를 찾고 해당 위치를 중심으로 새로운 context window에 들어가는 내용물을 만들어야했는데, 작성한 코드를 보면 이미 알고 있는 answer_start 정보로 컨택스트를 새로 재구성해 학습하는 식으로 작성했었습니다. 이렇게 되면 모델이 정답 위치를 예측하는 능력을 학습하는 것이 아니게 되어버립니다.
정답 context를 window 중심부에 배치하겠다는 생각에 집중한 나머지, 모델이 어떤 정보를 이용해 어떻게 학습을 하는지 잊고 구현했던 것 같습니다.
해결: Two-stage Reader 아키텍처
전처리 단계의 answer-aware window를 사용할 수 없었던 것은 모델이 학습시점에 정답 정보를 미리 활용했다는 점 때문이었습니다. 미리 알고 있는 정답 위치를 이용해 정답을 window의 중심부로 배치한 새로운 context를 만드는 것이 아니라, 정답 위치를 먼저 예측하고 해당 위치를 이용해 새로운 context를 만들어야 했습니다. 즉, 문제를 해결하기 위한 발상은 같지만 학습-추론 모델에 적용할 때는 정답 위치를 “미리 알고 있어야 한다”가 아니라, “정답의 가능성이 높은 것을 먼저 찾아낸 뒤 활용한다” 는 과정으로 설계를 해야 하는 것이었습니다.
따라서, 전처리 단계의 answer-aware 로직을 제거하고, 정상적으로 동작 가능한 Two-stage Reader 를 새로 설계했습니다.
아키텍처 개요
[Question + Context]
│
Stage 1: Coarse Reading
(Sliding Window로 전체 문서 스캔)
│
[정답 후보 위치 식별]
│
Stage 2: Refined Reading
(정답 후보 중심으로 window 재구성)
│
[Selection: F1 overlap + confidence 기반 최종 선택]
│
[Final Answer]
- Stage 1 (Coarse Reading): 기존 Sliding Window 방식으로 전체 문서를 스캔하여 정답 후보 영역을 식별
- Stage 2 (Refined Reading): Stage 1이 찾은 후보 위치를 중심으로 윈도우를 재구성하여 정밀 추론
- Selection: Stage 1과 Stage 2의 결과를 F1 overlap과 confidence로 비교하여 최종 답변 선택
핵심 구현: Token-level Window 생성
Token-level Window를 생성하는 과정에서 character 기준 근사값(한글 1.5자 ≈ 1토큰)을 사용하는 대신에 tokenization을 수행한 뒤 token index를 기준으로 window를 계산하였습니다.
당시에는 character 기준보다 token 단위로 처리하는 것이 더 정확하다고 판단했었습니다. 다만 지금 돌아보면, window에 들어가는 context가 매우 정교할 필요까지는 없는 덩어리 단위 정보였기 때문에 근사적으로 처리하는 방식이 코드 복잡도나 생산성 측면에서는 더 나았을 수도 있겠다는 생각이 듭니다.
# src/models/two_stage_reader.py
def _create_answer_centered_window(self, context, ans_char_start, ans_char_end, question=""):
"""Stage 1이 찾은 후보 위치 기반으로 token-level window 생성"""
question_tokens = self.tokenizer.tokenize(question) if question else []
available_tokens = self.stage2_target_tokens - len(question_tokens) - 3 # [CLS], [SEP], [SEP]
# Full context를 한 번에 tokenize하여 정확한 token-level offset 확보
full_encoded = self.tokenizer(
context, return_offsets_mapping=True, add_special_tokens=False
)
full_offsets = full_encoded["offset_mapping"]
# Answer span에 해당하는 token index 탐색
answer_token_start, answer_token_end = None, None
for i, (start, end) in enumerate(full_offsets):
if answer_token_start is None and start <= ans_char_start < end:
answer_token_start = i
if start < ans_char_end <= end:
answer_token_end = i
break
if answer_token_start is None or answer_token_end is None:
return None, 0
# 남은 토큰을 답변 전후로 배분
answer_token_len = answer_token_end - answer_token_start + 1
remaining_tokens = available_tokens - answer_token_len
left_tokens = int(remaining_tokens * self.answer_buffer_ratio)
right_tokens = remaining_tokens - left_tokens
# Token index로 window 계산
window_token_start = max(0, answer_token_start - left_tokens)
window_token_end = min(len(full_offsets), answer_token_end + 1 + right_tokens)
# Token index → Character offset 복원
window_char_start = full_offsets[window_token_start][0]
window_char_end = full_offsets[window_token_end - 1][1]
return context[window_char_start:window_char_end], window_char_start
첫 번째 시도와의 차이점:
| 항목 | 첫 번째 시도 (전처리 단계에서 answer-aware window) | 재설계 (Two-stage) |
|---|---|---|
| 정답 위치 | 학습 데이터에서 직접 참조 | Stage 1이 탐색 |
| 윈도우 계산 | character 기반 근사 | token-level 정밀 계산 |
| 추론 시 사용 | 불가능 | 가능 |
| offset 복원 | 불필요 | tokenize → token index → char offset |
최종 답변 선택 로직
Stage 1과 Stage 2의 결과를 다음 기준으로 비교합니다:
- Stage 2 결과가 비어있으면 → Stage 1 사용
- Stage 2 confidence가 임계값 미만 → Stage 1 사용
- Stage 1/2의 F1 overlap 계산:
- overlap이 높으면 → Stage 2 (정밀 추론 결과) 사용
- overlap이 낮으면 → Stage 1 (Stage 2가 엉뚱한 답을 냈다고 판단)
# src/models/two_stage_reader.py
# F1 overlap + confidence 기반 선택
final_predictions = {}
nbest_predictions = {}
stage2_used = 0
stage1_used = 0
for example_id in stage1_results:
stage1_text = stage1_results[example_id]["text"]
stage1_score = stage1_results[example_id]["score"]
stage2_text = stage2_results[example_id]["text"]
stage2_score = stage2_results[example_id]["score"]
stage2_confidence = stage2_results[example_id]["confidence"]
# 1) Stage2가 빈 답이면 Stage1 사용
if not stage2_text or not stage2_text.strip():
final_predictions[example_id] = stage1_text
stage1_used += 1
else:
# 2) Stage2 confidence가 너무 낮으면 Stage1 사용
if stage2_confidence < self.stage2_confidence_threshold:
final_predictions[example_id] = stage1_text
stage1_used += 1
else:
# 3) F1 overlap 계산
overlap_f1 = self._calculate_f1_overlap(stage1_text, stage2_text)
if overlap_f1 >= self.stage2_overlap_threshold:
# overlap 높으면 → Stage2 (정밀 추론) 사용
final_predictions[example_id] = stage2_text
stage2_used += 1
else:
# overlap 낮으면 → Stage1 (Stage2가 엉뚱한 답을 냄)
final_predictions[example_id] = stage1_text
stage1_used += 1
def _calculate_f1_overlap(self, text1: str, text2: str) -> float:
"""두 텍스트 간의 F1 overlap 계산"""
tokens1 = text1.split()
tokens2 = text2.split()
common = set(tokens1) & set(tokens2)
if len(common) == 0:
return 0.0
precision = len(common) / len(tokens2)
recall = len(common) / len(tokens1)
f1 = 2 * precision * recall / (precision + recall)
return f1
실험 결과
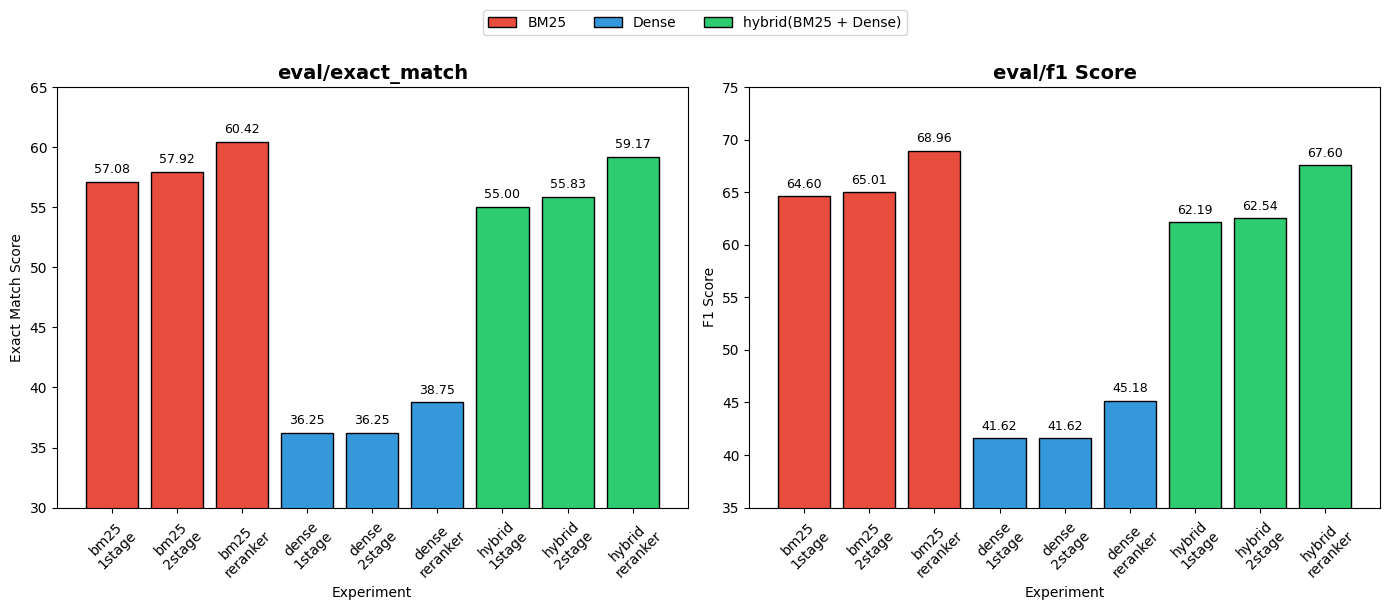
Retriever(BM25/Dense/Hybrid) × Reader(1-stage/2-stage) × Reranker 조합을 전수 비교했습니다.
| 파이프라인 | EM | F1 |
|---|---|---|
| BM25_1stage | 57.08 | 64.60 |
| BM25_2stage | 57.92 | 65.01 |
| BM25_2stage_reranker | 60.42 | 68.96 |
| Dense_1stage | 36.25 | 41.62 |
| Dense_2stage | 36.25 | 41.62 |
| Dense_2stage_reranker | 38.75 | 45.18 |
| Hybrid_1stage | 55.00 | 62.19 |
| Hybrid_2stage | 55.83 | 62.54 |
| Hybrid_2stage_reranker | 59.17 | 67.60 |
결과 해석
Two-stage 구조를 적용했을 때, BM25와 Hybrid Retriever에서 EM/F1이 소폭 상승하는 것을 확인할 수 있었습니다. Stage 2에서 정답 후보 주변으로 문맥을 재구성함으로써, 기존 Sliding Window가 가지고 있던 경계 문제와 irrelevant 문맥에 의한 attention 분산이 완화되었기 때문이라 생각합니다.
특히, Two-stage + Reranker 조합에서 성능 향상이 가장 크게 나타났는데, 이는 Reranker가 top-k 문서의 질을 먼저 높여주기 때문에 Stage 1에서의 후보 위치 탐색이 보다 정확해지고, Stage 2는 이미 더 정확한 문서에서 정답 중심의 정밀한 추론을 수행할 수 있기 때문이라고 보았습니다. 즉, Reranker는 입력의 품질을 높이고, stage 2가 추론의 정밀도를 높이는 방식으로 시너지를 냈다고 해석할 수 있을 것 같습니다.
반면, Dense Retriever 계열에서는 Two-stage 적용에 의한 개선이 나타나지 않았습니다. Two-stage의 구조가 효과를 내기 위해서는 Stage1에서 정답이 포함된 문서가 상위에 올라오는 것이 전제되어야 하는데, Dense Retriever 자체의 검색 성능이 충분하지 않아 개선 효과가 나타나지 않았다고 판단하였습니다.
마무리
이번 글에서는 Sliding Window의 구조적 한계인 맥락 불균형, irrelevant 문맥 증가, negative chunk 누적 문제 를 해결하기 위해 Two-stage Reader를 설계하고 구현한 과정을 정리했습니다.
처음에는 학습 전처리 단계에서 정답 위치를 직접 참조하는 방식을 시도했지만, 실제로는 사용할 수 없다는 근본적인 문제를 발견하고 Stage 1에서 정답 후보를 먼저 탐색한 뒤 Stage 2에서 정밀 추론하는 구조로 재설계했습니다.
실험 결과들을 통해 Two-stage 구조가 성능 개선에 도움이 된다는 것도 확인 할 수 있었지만, 더 흥미로웠던 점은 Two-stage 구조의 효과가 결국 Stage 1의 검색 품질에 강하게 의존한다는 사실이었습니다. BM25처럼 1-stage에서 정답이 포함된 문서를 비교적 잘 상위에 올려주는 경우에는, Reranker와의 시너지까지 더해져 큰 폭의 성능 향상이 나타났지만, Dense Retriever처럼 검색 성능 자체가 충분하지 않은 경우에는 Stage 2에서 아무리 정밀하게 추론하더라도 개선 효과가 제한적이었습니다.
결국 Two-stage 구조는 각 단계가 독립적으로 성능을 내는 구조가 아니라, 앞 단계의 품질이 뒷 단계의 성능 상한을 결정하는 구조라는 점을 확인할 수 있었던 흥미로운 실험이었습니다.