[ODQA] BM25 Tokenizer 비교 실험 & Retriever 평가
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
BM25 Tokenizer 비교 실험
실험 동기
BM25는 대표적인 sparse 검색 방식으로, 질의어가 문서에 얼마나 자주 등장하는지와 해당 단어가 전체 문서 집합에서 얼마나 희소한지를 반영해 문서의 관련도를 계산합니다. 이 과정은 토큰 단위 매칭에 기반하므로, tokenizer가 생성하는 토큰의 단위(granularity)에 따라 문서 순위와 retrieval 품질이 직접적으로 달라질 수 있습니다.
특히, 한국어는 조사와 어미가 발달한 교착어이기 때문에, 공백 단위의 분절이 의미 단위와 일치하지 않는 경우가 많습니다. 예를 들어:
"서울에서" → 공백 분절: ["서울에서"] (조사 포함)
→ 형태소: ["서울", "에서"] (의미 단위 분리)
→ 서브워드: ["서울", "##에서"] (모델 학습 기반)
이처럼 한국어는 조사, 어미, 활용 등으로 표면형 변화가 큰 언어이므로, 이러한 형태적 특성을 반영한 형태소 기반 tokenizer가 BM25의 lexical matching 방식과 더 잘 맞물릴 가능성이 있을 것이라 생각했습니다. 즉, 형태소 단위 토큰화가 질의와 문서 간 어휘 일치를 더 정확하게 포착해 retrieval 성능 향상에 기여할 것이라 가설을 세우고 비교 실험을 진행하였습니다.
실험 설계 및 구현
Tokenizer 5종
| 유형 | Tokenizer | 특징 |
|---|---|---|
| 서브워드 | klue/BERT, klue/RoBERTa | HuggingFace 모델의 WordPiece/BPE tokenizer |
| 형태소 | Mecab (python-mecab-ko) | 한국어 형태소 분석기 |
| 형태소 변형 | morpheme_nouns, morpheme_content | 명사만 / 내용어만 추출 |
| 음절 | Character | 글자 단위 분절 |
| 공백 | Whitespace | 띄어쓰기 단위 분절 |
구현
HuggingFace 기반 tokenizer와 공백, 문자, 형태소 분석기 기반의 커스텀 tokenizer를 모두 지원하도록 구현하였고, 특히 한국어 형태 정보를 반영하는 MeCab 기반 tokenizer를 함께 실험할 수 있도록 구성하였습니다. 또한 MeCab 객체를 전역에서 캐싱해 반복 호출 시 인스턴스를 매번 새로 생성하지 않도록 하여, 대량 문서 처리 과정의 오버헤드를 줄였습니다.
# miscellaneous/build_bm25_indices.py
# HuggingFace 모델 기반 토크나이저
TOKENIZERS = {
"klue_bert": "klue/bert-base",
"klue_roberta": "klue/roberta-base",
}
# 커스텀 토크나이저 정의
def whitespace_tokenizer(text):
return text.split()
def character_tokenizer(text):
return list(text.replace(" ", ""))
# MeCab 인스턴스 캐싱 (전역 변수)
_mecab_instance = None
def get_mecab():
global _mecab_instance
if _mecab_instance is None:
from mecab import MeCab
_mecab_instance = MeCab()
return _mecab_instance
def morpheme_tokenizer(text):
"""형태소 분석기 - 전체 형태소"""
return get_mecab().morphs(text)
def morpheme_nouns_tokenizer(text):
"""형태소 분석기 - 명사만 추출"""
return get_mecab().nouns(text)
def morpheme_content_words_tokenizer(text):
"""형태소 분석기 - 내용어만 추출 (명사/동사/형용사)"""
pos_tags = get_mecab().pos(text)
return [
word for word, pos in pos_tags
if (pos[0] == 'N' and len(word) > 1) or # 명사 2글자 이상
(pos[0] in ['V', 'M', 'X']) # 동사/형용사/어근
]
CUSTOM_TOKENIZERS = {
"whitespace": whitespace_tokenizer,
"character": character_tokenizer,
"morpheme": morpheme_tokenizer,
"morpheme_nouns": morpheme_nouns_tokenizer,
"morpheme_content": morpheme_content_words_tokenizer,
}
- HuggingFace 모델 tokenizer는 모델명으로 로드하고, 나머지 커스텀 tokenizer는 함수로 직접 정의했습니다.
- 형태소 기반 tokenizer는 MeCab을 사용하되, 전체 형태소 / 명사만 / 내용어만 추출하는 세 가지 변형을 두어 형태소 분석의 granularity에 따른 차이도 비교할 수 있도록 했습니다.
- MeCab 인스턴스는 매 호출마다 생성하면 비용이 크기 때문에 전역 캐싱 방식으로 처리했습니다.
# scripts/evaluate_retrievers.py
def discover_bm25_indices(data_path="data"):
"""data 폴더에서 bm25_embedding_*.bin 파일들을 자동으로 탐지"""
pattern = os.path.join(data_path, "bm25_embedding_*.bin")
files = glob.glob(pattern)
indices = {}
# ...파일명에서 index_name 추출 후 반환
return indices # {index_name: file_path}
# 탐지된 모든 인덱스에 대해 자동 평가
if args.auto_detect_bm25:
bm25_indices = discover_bm25_indices("data")
for index_name in sorted(bm25_indices.keys()):
results = evaluate_sparse_model(
"bm25", eval_dataset, contexts,
tokenizer=shared_tokenizer,
model_name=f"BM25-{index_name}",
index_name=index_name,
)
all_results[f"BM25-{index_name}"] = results
평가 지표
- Recall@K (K=1, 5, 10, 20, 50): 상위 K개 문서 중 정답이 포함된 비율
- MRR (Mean Reciprocal Rank): 정답이 처음 등장하는 순위의 역수 평균
BM25 Tokenizer 비교 결과
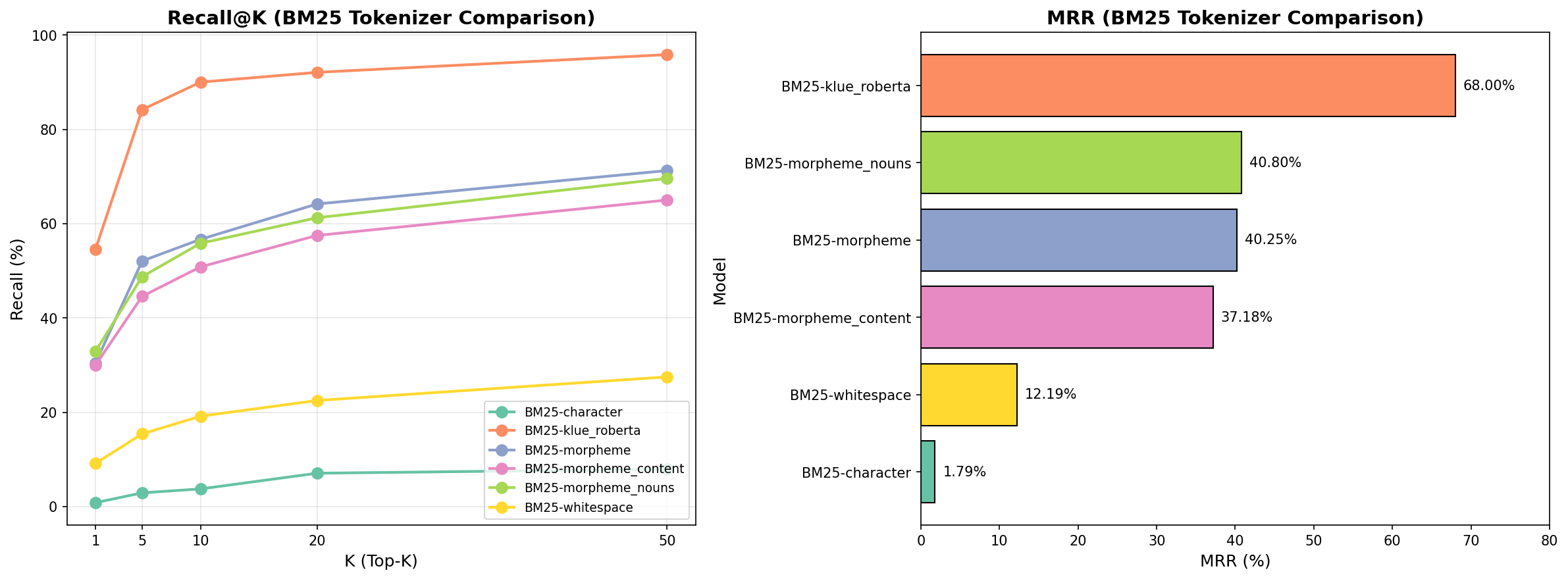
| Tokenizer | Recall@10 | MRR |
|---|---|---|
| klue/RoBERTa (서브워드) | ~90% | ~68% |
| morpheme_nouns (명사) | ~49% | ~41% |
| morpheme (형태소) | ~48% | ~40% |
| whitespace (공백) | ~32% | ~17% |
| character (문자) | ~2% | ~1% |
예상과 달리, 서브워드 기반 tokenizer(klue/RoBERTa) 가 형태소 기반보다 압도적으로 우수한 성능을 보였습니다.
서브워드가 우수한 이유 서브워드 tokenizer는 query와 문서에 등장하는 핵심 어휘를 비교적 일관된 단위로 분절하여, 보다 안정적인 lexical matching을 가능하게 한 것으로 보입니다.
형태소 기반이 부진한 이유 형태소 기반 tokenizer는 한국어의 언어적 특성을 잘 반영할 것이라 예상했지만, 실제로는 query와 document가 같은 의미를 가지더라도 서로 다른 토큰으로 분절되는 경우가 있었던 것으로 생각됩니다. 특히 MeCab의 분석 결과는 문맥에 따라 달라질 수 있어, 이 과정에서 query-document 간 토큰 불일치가 발생했고, 이것이 retrieval 성능 저하로 이어졌을 것이라 해석했습니다.
공백/문자 기반이 실패한 이유 공백 기반 tokenizer는 한국어의 형태적 특성을 충분히 반영하지 못했고, 문자 기반 tokenizer는 토큰을 지나치게 잘게 나누어 버려 의미 있는 단위의 매칭이 어려웠던 것으로 보입니다. 그 결과, 두 방식 모두 BM25가 효과적으로 문서를 구분하고 순위를 매기는 데 한계가 있었던 것으로 해석됩니다.
Retriever 종류별 비교 실험
실험 동기
학습 데이터의 정답 유형 분포를 분석한 결과, 일반명사(40.6%)와 고유명사(25.1%)가 가장 높은 비율을 차지했으며, 이 둘의 조합까지 포함하면 전체 정답의 85.9%가 명사 기반이었습니다. 또한 숫자/수사 유형도 13.0%로 일정 비율을 차지한 반면, 외국어나 기타 유형은 극소수였습니다. 이는 정답의 대부분이 긴 문장보다는 짧고 구체적인 명사구 또는 숫자 표현으로 이루어져 있음을 의미합니다.
이러한 데이터 특성을 고려했을 때, 의미적 유사성을 넓게 포착하는 Dense Retriever보다 질문과 문서 간 lexical overlap을 직접 반영하는 Sparse Retriever가 더 유리할 가능성이 있다고 판단하였습니다. 즉, 질문에 포함된 핵심 표현이 문서에 그대로 등장하는 경우가 많다면, 의미 공간에서의 근접성보다 실제 단어의 일치 여부가 retrieval 성능에 더 큰 영향을 줄 수 있다고 생각했기 때문입니다.
따라서 이번 비교 실험은 EDA를 통해 확인한 데이터 특성이 실제 Retriever 성능 차이로 이어지는지 검증하기 위한 과정이기도 했습니다.
구현
BM25 Tokenizer 비교 실험과 함께, 각 Retriever 종류(TF-IDF, BM25, Dense, Hybrid)의 성능을 동일한 기준으로 비교 평가했습니다.
# scripts/evaluate_retrievers.py — 핵심 평가 로직
def evaluate_sparse_model(model_type, eval_dataset, contexts, tokenizer=None,
k_values=[1, 5, 10, 20, 50], model_name="Sparse", index_name=None):
"""Sparse Retriever 평가 (BM25, TF-IDF, Hybrid)"""
if model_type.lower() == "bm25":
retriever = BM25Retriever(tokenize_fn=tokenizer.tokenize, data_path="data", index_name=index_name)
elif model_type.lower() in ["tfidf", "tf-idf"]:
retriever = TFIDFRetriever(tokenize_fn=tokenizer.tokenize, data_path="data")
retriever.get_sparse_embedding()
queries = [s["question"] for s in eval_dataset]
doc_scores, doc_indices = retriever.get_relevant_doc_bulk(queries, k=50)
for i, sample in enumerate(eval_dataset):
gold_context = sample["context"]
retrieved = [retriever.contexts[idx] for idx in doc_indices[i]]
recalls, mrr = calculate_metrics_for_sample(retrieved, gold_context, k_values)
...
최종 비교
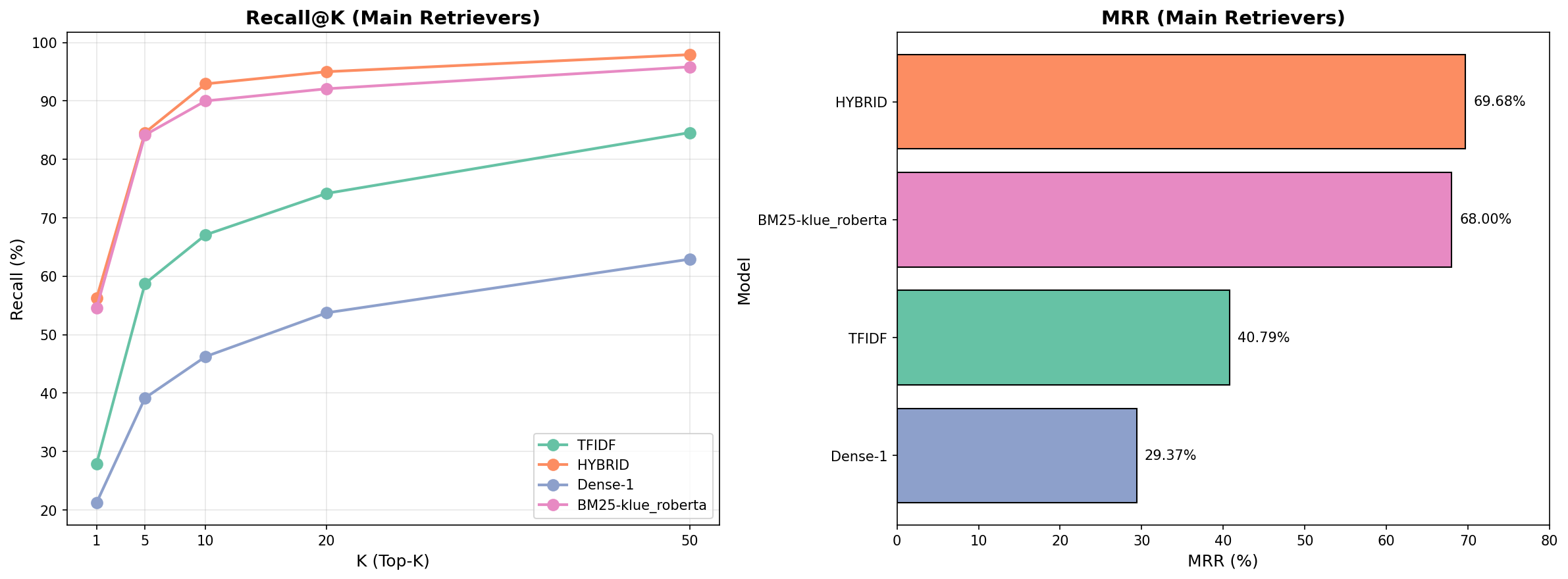
BM25, TF-IDF, Dense, Hybrid Retriever를 비교한 결과, BM25 기반 Retriever가 전반적으로 가장 안정적인 성능을 보였으며 Dense Retriever는 상대적으로 낮은 성능을 기록했습니다.
- 정답 형태가 일반명사나 고유명사가 많고, 질문에 있는 단어가 context에 그대로 등장하는 lexical overlap이 높아 BM25에 유리한 데이터 특성 때문에 BM25가 성능이 좋게 나온 것으로 보입니다.
- Dense Retriever는 학습 과정에서 Hard Negative를 고려한 학습이 이루어지기 전이라, 의미적으로 유사한 오답 문서에 취약했던 것으로 추측했습니다.
| 모델 | Validation EM | Leaderboard EM | 비고 |
|---|---|---|---|
| Sparse (BM25) | 59.58% | 56.25% | 키워드 매칭 우수 |
| Dense (Bi-Encoder) | 33.75% | - | 학습 부족으로 성능 저조 |
| Hybrid (0.7/0.3) | 57.08% | 58.33% | Leaderboard 최고 성능 |
리트리버 단독이 아닌 전체 과정에서 보여주는 성능은 Validation 데이터에서 BM25 단독이 최고, Leaderboard에서는 Hybrid가 최고 로 나타났습니다.
마무리
이번 실험을 통해 몇 가지 흥미로운 점을 확인할 수 있었습니다. 먼저, “한국어이기 때문에 형태소 분석 기반 tokenizer가 더 유리할 것”이라는 직관이 항상 맞는 것은 아니라는 점입니다. 오히려 BM25에서는 의미 단위를 얼마나 정교하게 나누느냐보다, query와 document가 얼마나 일관된 기준으로 토큰화되어 매칭되느냐 가 더 중요하게 작용했습니다.
또한 EDA에서 확인한 정답 유형 분포 역시 retrieval 실험 결과를 해석하는 데 중요한 단서가 되었습니다. 정답의 대부분이 일반명사, 고유명사, 숫자처럼 비교적 표면형이 뚜렷한 형태였기 때문에, 의미 공간에서의 추상적 유사성보다 실제 단어의 직접적인 일치 여부가 더 중요하게 작용했을 가능성이 큽니다. 이런 점에서 Sparse Retriever가 강세를 보였다는 결과는 어느 정도 예상과 맞아떨어졌다고 볼 수 있었습니다.
같은 BM25라도 tokenizer에 따라 Recall@10이 2%대에서 90%대까지 크게 차이날 수 있다는 결과를 통해, retrieval 성능 개선에서는 알고리즘 자체만큼이나 tokenizer 선택 역시 핵심 요소임을 확인할 수 있었습니다.
Retriever 비교 결과도 인상적이었습니다. lexical overlap이 높은 데이터셋 특성상, 단일 retriever 기준으로는 BM25가 가장 안정적인 성능을 보였습니다. 반면 Leaderboard 기준으로는 Dense Retriever와 결합한 Hybrid 방식이 가장 높은 성능을 기록했습니다. 이는 단독으로는 한계가 있었던 Dense Retriever도 BM25와 결합했을 때 상호 보완 효과를 낼 수 있음을 보여줍니다.
결국 각 retriever는 서로 다른 강점을 가지며, 단일 방식에만 의존하기보다 적절한 조합을 통해 더 나은 성능을 얻을 수 있다는 점을 확인할 수 있었습니다.
개인적으로 이번 프로젝트에서 가장 큰 수확은 성능 수치 자체보다도, 문제를 정의하고 가설을 세운 뒤 이를 검증하기 위한 실험을 직접 설계하고 수행해본 경험이었습니다. 아직 부족한 점은 많지만, 단순히 구현에 그치지 않고 왜 이런 결과가 나왔는지 해석해보려 했다는 점에서 의미 있는 과정이었다고 생각합니다.