[CSAT-Solver] LLM 기반 데이터 증강 — Prompt Engineering과 Fine-tuning
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
EDA에서 발견한 데이터 편향과 부족 문제를 해결하기 위해 LLM 기반 데이터 증강 파이프라인을 구축한 과정을 다룹니다.
문제 인식
EDA 결과를 종합하면, 기존 학습 데이터에는 다음과 같은 문제점이 명확했습니다.
- 질문 유형이 사실 관계 확인에 편중, 부정형/순서 찾기/다수 선택지 문제 부족
<보기>(question_plus)가 포함된 문제가 없음- 문장이 끊기거나 성립 불가능한 문제 등 학습 데이터로 쓸 수 없는 것들이 존재
단순한 양 증가가 아니라 EDA에서 발견한 부족 유형을 중심으로 질문 유형과 지문 분포의 다양성 확보를 목표로 데이터 증강을 진행했습니다.
1단계: Prompt Engineering 기반 문제 생성
지문 선정
가장 먼저 고민한 것은 어떤 지문을 입력으로 사용할 것인가였습니다. 기존 train data의 지문이 상당수 신문 기사 기반이라는 점을 확인하고, 지문 소스를 다음과 같이 구성했습니다.
- 기존 데이터의 분포를 유지하기 위해 신문 말뭉치 포함
- 수능형 국어 지문 특성을 반영하기 위해 문어 말뭉치(설명문·논설문 성격 텍스트) 추가
- AIHub의 국어 지문형 문제 데이터셋은 별도 가공 없이 학습 데이터에 직접 포함
파이프라인 구현
GPT-4o-mini API를 활용한 문제 생성 파이프라인을 구축했습니다. 신문/도서 JSON 파일을 로드하고, 기사 단위로 파싱한 뒤 OpenAI Batch API로 문제를 생성하는 구조입니다.
# src/data/data_augmentation.py — 신문 데이터 로드 및 파싱
def load_newspaper_data(file_path: str) -> List[Dict[str, Any]]:
"""신문 JSON 파일을 로드하고 기사 단위로 재구성"""
articles = []
json_files = list(Path(file_path).glob("*.json"))
for json_file in track(json_files, description="Parsing JSON files"):
with open(json_file, "r", encoding="utf-8") as f:
data = json.load(f)
for doc in data.get("document", []):
# 흩어져있는 paragraph들을 합쳐서 하나의 content로 만들기
paragraphs = doc.get("paragraph", [])
content = "\n".join([
p.get("form", "").replace("<p>", "").replace("</p>", "").strip()
for p in paragraphs
])
if len(content) < 200: # 너무 짧은 본문은 제외
continue
articles.append({
"article_id": doc.get("id"),
"title": doc.get("metadata", {}).get("title", ""),
"content": content,
"topic": doc.get("metadata", {}).get("topic", ""),
})
return articles
def create_batch_request_file(articles, output_file, num_problems=2000, seed=42):
"""OpenAI Batch API에 제출할 JSONL 요청 파일 생성"""
set_seed(seed)
num_articles_needed = min(len(articles), num_problems)
selected_articles = random.sample(articles, num_articles_needed)
# 각 기사에 대해 프롬프트를 생성하여 JSONL로 저장
...
- 200자 미만의 짧은 기사는 문제 생성에 적합하지 않다고 판단하여 필터링
- 목표 문제 수에 맞게 기사를 랜덤 샘플링한 뒤 OpenAI Batch API 규격의 JSONL로 저장
- 개별 API 호출 대신 Batch API를 사용한 이유는 비용 절감 때문으로, 동일한 모델 기준 Batch API는 일반 호출 대비 약 50% 저렴하며, 대량의 문제를 생성하는 상황에서 비용 부담을 크게 줄일 수 있음
프롬프트 설계
EDA에서 부족하다고 판단한 질문 유형을 중심으로 few-shot 예제를 직접 설계했습니다.
추가하고 싶었던 문제 유형:
<보기>를 활용한 문제- 부정형 질문
- 선지 조합형 문제 (ㄱ, ㄴ, ㄷ)
- 순서 배열 문제
- 외부 개념이나 이론을 적용해야 하는 추론형 문제
프롬프트 설계 시 가장 신경 쓴 부분:
- 지문 외 정보의 무분별한 추론 방지 — 지문에 명시된 정보만을 사용하도록 강한 제약
<보기>의 역할 명확화 — 지문 요약이나 정답 힌트가 아닌, 판단 기준·이론·외부 개념을 제공하는 경우에만 생성하도록 제한
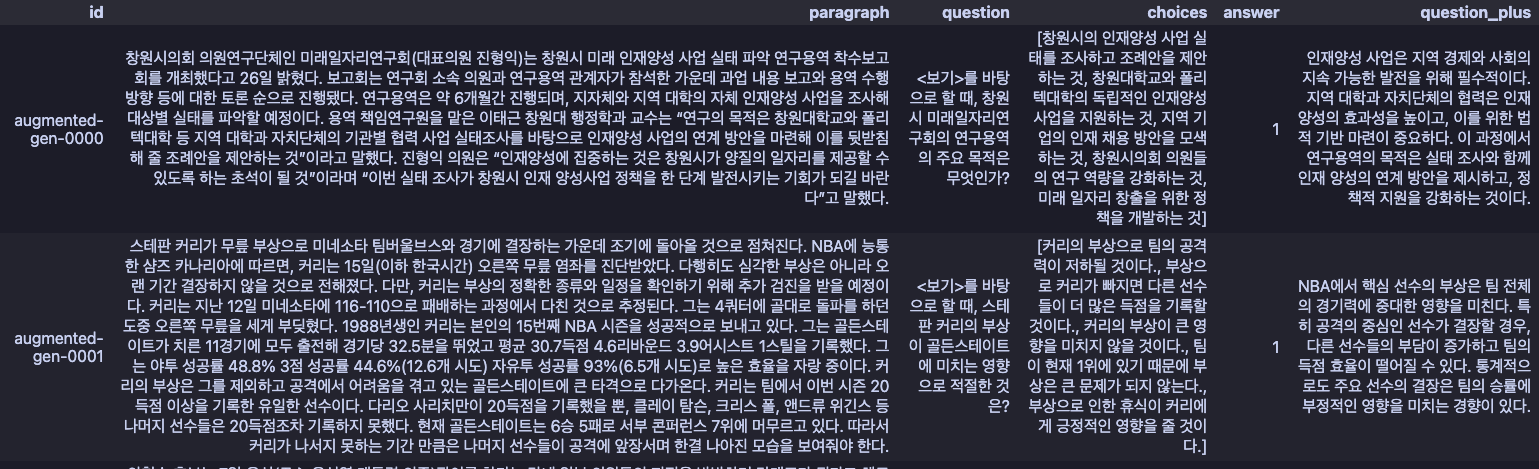

결과적으로 문제의 형식적 완성도와 유형 다양성은 만족스러운 수준으로 생성되었습니다.
2단계: GPT-4o-mini Fine-tuning 기반 문제 생성
이후 GPT-4o-mini API 자체도 fine-tuning이 가능하다는 점을 알게 되었고, 기존의 training_data와 AIHub의 국어 지문형 데이터셋에서 2000개를 선별해 파인튜닝을 진행하였습니다.
데이터 준비부터 업로드, 학습, 모니터링까지 전 과정을 파이프라인으로 구성하였습니다.
# src/data_gen/prepare_finetuning_data.py — Fine-tuning 데이터 준비
class FineTuningDataPreparer:
"""CSV 데이터를 OpenAI Fine-tuning JSONL 형식으로 변환"""
def __init__(self, csv_path: str, output_dir: str = "data/finetuning"):
self.system_message = "당신은 지문으로 수능형 객관식 문제를 생성하는 전문가입니다."
self.user_template = """다음 지문을 읽고 JSON 형식으로 문제를 생성하세요.
**출력 형식:**
paragraph
지문:
{paragraph}"""
def load_top_quality_data(self, top_n: int = 2000) -> pd.DataFrame:
"""total_score 상위 N개 데이터 로드"""
df = pd.read_csv(self.csv_path)
return df.sort_values("total_score", ascending=False).head(top_n)
- 1단계에서 생성한 문제에 대해 LLM으로 품질 평가(scoring)를 수행한 뒤,
total_score상위 N개만 선별하여 fine-tuning 데이터로 사용했습니다. - user 메시지에는 지문만 제공하고, assistant 메시지에는 문제·선택지·정답·보기를 JSON 형태로 포함시켜 출력 형식을 학습하도록 설계했습니다.
# run_gpt_api_finetuning.py — Fine-tuning 실행
class FineTuningRunner:
def run(self, train_file, val_file, model="gpt-4o-mini-2024-07-18",
suffix="ksat-qa-finetuned", monitor=True):
# 1. 파일 업로드
self.training_file_id = self.upload_file(train_file)
self.validation_file_id = self.upload_file(val_file)
# 2. 파일 처리 대기
self.wait_for_file_processing(self.training_file_id)
# 3. Fine-tuning 작업 생성
self.job_id = self.create_finetuning_job(
training_file_id=self.training_file_id,
validation_file_id=self.validation_file_id,
model=model, suffix=suffix,
hyperparameters={"n_epochs": "auto"},
)
# 4. 실시간 모니터링
if monitor:
job = self.monitor_job(self.job_id)
return job
n_epochs: "auto"로 설정하여 OpenAI가 데이터 크기에 맞게 최적 epoch 수를 자동 결정하도록 함- 이벤트 로그를 실시간으로 출력하여 학습 진행 상황을 터미널에서 확인 가능
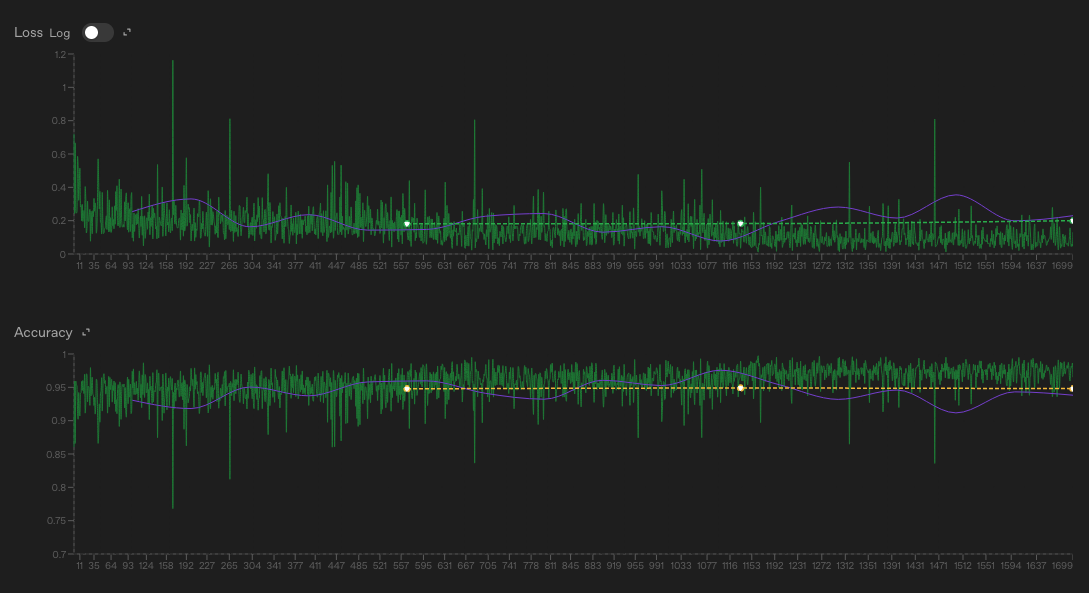
- train_data: 1699개 데이터 / validation_data: 299
- Accuracy는 초기부터 높은 수준을 유지하며 큰 변동 없이 안정적으로 수렴함
- Loss는 전반적으로 낮은 값에서 유지되며 학습 발산 없이 수렴 양상을 보임
- LLM 모델 자체 성능이 좋아 급격한 성능 향상보다 출력 안정성과 분포 적응이 중심인 학습 결과로 판단됨
- 문제 생성 및 데이터 증강용 베이스 모델로 활용하기에 적합하다고 판단

생성 결과를 분석한 결과, 질문에서는 “<보기>를 참고하여”라는 표현이 포함되었음에도 실제 출력에서는 <보기>가 생성되지 않거나 형식적으로만 나타나는 문제가 반복되었습니다. 파인튜닝이 <보기> 포함 문제의 표면적 형식에는 익숙해졌으나, <보기>를 독립적인 정보 단위로 생성해야 하는 조건부 출력 구조까지는 충분히 학습하지 못한 것으로 판단했습니다.
fine-tuning 방식으로 생성한 데이터는 최종적으로 사용하지 않았습니다.
데이터 품질 관리(QC)의 한계
이번 증강에서 가장 아쉬운 점은 생성된 문제의 품질을 평가하고 정제하는 기준을 끝까지 체계화하지 못했다는 것 입니다. 여러 LLM API를 활용해 생성된 문제를 풀어보거나 정답의 타당성을 점검하는 시도까지는 진행했습니다. 그러나 품질이 낮은 데이터를 어떤 기준으로 제외할지, 검수 결과를 실제 데이터셋 정제에 어떻게 반영할지에 대한 명확한 원칙은 마련하지 못했습니다. 그 결과 검토는 했지만 최종적으로 걸러내지 못한 데이터가 남아 있었고, 이는 학습 데이터의 일관성을 떨어뜨릴 수 있는 요소로 작용했습니다.
돌이켜보면 당시에는 데이터를 임의로 제외하는 과정이 결과를 유리하게 보이도록 조작한다는 선택처럼 느껴져 다소 조심스러웠습니다. 하지만 지금은 그 과정이 단순한 선택적 사용이 아니라, 학습 데이터의 신뢰성과 효용을 높이기 위한 필수적인 품질 관리 단계로 보는 편이 더 맞다고 생각합니다. 특히 생성형 모델을 활용한 데이터 증강에서는 “많이 만드는 것”보다 “학습 가능한 품질의 데이터를 남기는 것”이 더 중요하다는 점을 이번 경험을 통해 분명히 배울 수 있었습니다. 또한, 생물학 전공으로 실험을 수행해 온 경험 때문에, 데이터를 임의로 버리거나 골라내는 것(cherry-picking)에 대한 거부감이 강해서 더더욱 처리를 하지 않았던 것 같습니다.
학습 결과
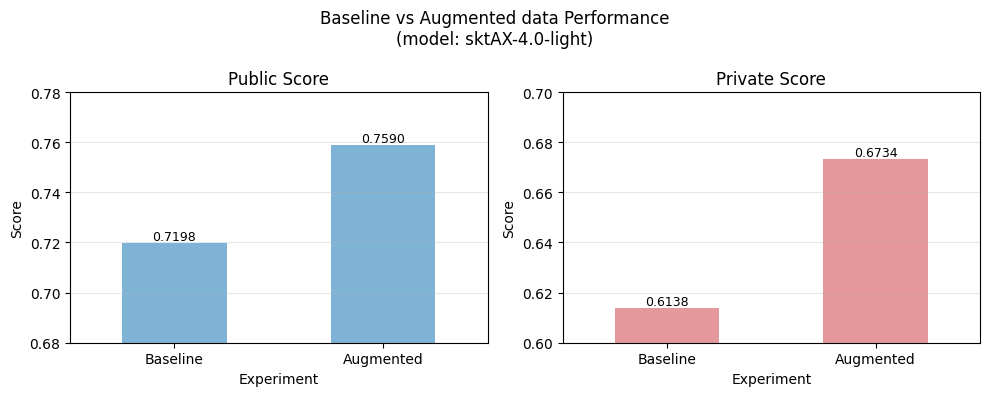
QC가 완전하지 않았음에도, 생성한 데이터셋을 기존 학습 데이터에 추가하여 학습한 결과 일관된 성능 향상이 확인되었습니다. Macro F1 은 0.6138 → 0.6734 로 개선되었고, Public Score 는 약 +0.04p , Private Score 는 약 +0.06p 상승 했습니다.
특히 Private Score의 개선 폭이 더 크게 나타났다는 점에서, 데이터 증강을 통해 과적합이 일부 완화되고 일반화 성능이 개선된 것으로 판단했습니다.
마무리
이번 데이터 증강 작업은 단순히 학습 데이터를 늘리는 과정이 아니라, EDA를 통해 확인한 데이터의 부족한 지점을 실제 실험 설계로 연결해본 과정 이었다는 점에서 의미가 있었던 것 같습니다. Prompt Engineering 기반 생성에서는 few-shot prompt를 적용하는 등 부족한 문제 유형과 <보기> 문항을 보완하려 했고, Fine-Tuning 기반 생성에서는 출력 형식의 안정성 과 분포 적응 가능성 을 확인했습니다.
동시에 QC 기준을 끝까지 정교하게 세우지 못한 한계도 분명히 드러났습니다. 이번 경험을 통해, 데이터 증강에서 중요한 것은 단순한 양적 확대가 아니라 문제 구조를 먼저 파악하고, 그에 맞는 생성 전략과 품질 관리 기준을 함께 설계하는 것 이라는 점을 배울 수 있었습니다. 결국 이번 프로젝트는 데이터를 만들고 넣어보는 수준을 넘어, 문제를 정의하고, 가설을 세우고, 실험을 통해 검증하는 과정을 단계적으로 연습해볼 수 있었던 작업이었고, 앞으로는 이 경험을 바탕으로 생성 데이터의 QC 체계와 실험 설계를 더 정교하게 발전시켜 나가고자 합니다.