[CSAT-Solver] MoA 파이프라인 설계 — llama.cpp 환경 구축과 다단계 추론
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
제한된 GPU 환경에서 대형 모델의 추론 능력을 확장하기 위해, MoA(Mixture-of-Agents)와 유사한 구조를 설계하고 llama.cpp 기반 서버 환경을 구축한 과정을 정리합니다.
실험 목적
이번 프로젝트를 진행하면서 제한된 리소스 환경에서 대형 모델의 추론 능력을 확장할 수 있는 방법에 대해서 많이 고민하였습니다. 이전에 Mixture-of-Agents(MoA) 라는 논문에 대해서 공부한 적이 있었는데, 저희 환경에서도 그와 유사한 구조를 구현해볼 수 있겠다는 생각이 들었습니다.
따라서, MoA와 유사한 구조를 단일 파이프라인 형태 로 구성해서, 여러 모델을 병렬적으로 운용하기 어려운 상황에서도 역할을 분리한 추론 구조를 만들고자 했습니다. 이를 통해 단일 대형 추론 모델만 사용하는 경우와 비교했을 때, 정답 선택의 안정성과 일관성을 개선하고자 하였습니다.
환경 제약과 설계 판단
리소스 제약
실험 환경은 다음과 같았습니다.
- GPU: V100 32GB x 1
- 디스크: 총 50GB
이 환경에서는 하나의 대형 모델만 안정적으로 운용하는 것도 부담이 있었기 때문에, 여러 모델을 동시에 올려 복잡한 멀티 에이전트 구조를 구성하기는 어려웠습니다. 실제로 파이프라인을 구성할 수 있는 현실적인 상한은 7~8B급 모델 1개와 32B급 모델 1개를 조합하는 수준 이라고 판단했습니다.
따라서, 이번 설계는 “이상적인 다중 에이전트 구조”보다는 단일 GPU 환경에서 실제로 돌아갈 수 있는 구조 를 만드는 데 초점을 두었습니다.
모델 역할 배치
MoA 논문에서는 Aggregator의 성능이 전체 시스템 성능에 결정적인 영향을 미치며, Provider의 품질이 다소 낮더라도 강력한 Aggregator가 이를 수렴하고 정제할 수 있다고 설명합니다.
이 점을 참고하여, Aggregator에는 복합 추론 성능이 강한 32B급 모델을 배치하고, Provider에는 상대적으로 가볍고 빠르고 다양한 분석 정보를 생성할 수 있는 경량 모델을 배치하였습니다. 32B급 모델 선정에는 ArtificialAnalysis.ai 의 지표를 참고했습니다.
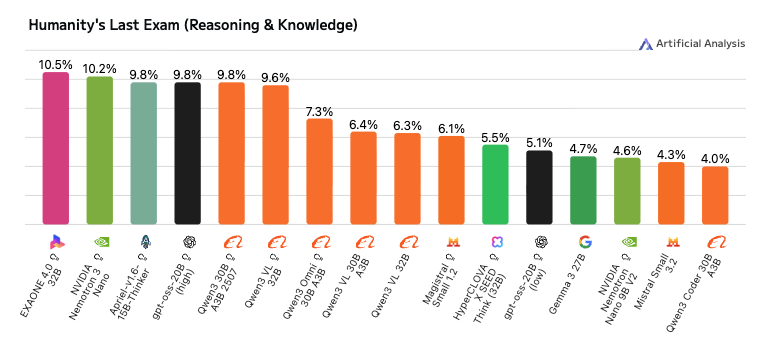
최종적으로 다음과 같이 모델과 역할을 배치하였습니다.
| 역할 | 모델 | 선정 이유 |
|---|---|---|
| Provider | skt/A.X-4.0-Light | 경량 모델, 빠른 생성 |
| Aggregator | EXAONE-4.0-32B | 복합 추론 벤치마크에서 강점 |
단일 Provider의 다중화
원래의 MoA 구조에서는 여러 Provider가 서로 다른 관점의 출력을 생성하지만, 단일 GPU 환경에서 여러 Provider 모델을 동시에 띄우기 어려웠습니다. 그래서 하나의 Provider 모델에 서로 다른 temperature를 적용해 복수의 관점을 생성하는 방식 으로, 다중 Provider의 효과를 간접적으로 모사했습니다. 즉, 모델 자체는 하나지만 생성 설정을 달리해 보다 분석적인 관점과 보다 탐색적인 관점을 각각 만들고, 이를 Aggregator가 종합하도록 구성하였습니다. 완전한 형태의 MoA는 아니지만, 제한된 환경에서 다중 관점 생성을 구현하기 위한 현실적인 타협이었습니다.
llama.cpp 기반 서버 환경 구축
EXAONE-4.0-32B를 V100 단일 GPU에서 추론하기 위해, llama.cpp CUDA 빌드 기반 서버를 직접 구성했습니다. 32B급 모델을 일반적인 방식으로 사용하기에는 메모리 여유가 부족했기 때문에, GGUF 포맷의 양자화 모델을 사용해 VRAM 사용량을 줄이고 단일 GPU 내에서 안정적으로 로딩 및 추론이 가능하도록 구성하였습니다. 그 결과, 32B VRAM 환경에서도 EXAONE-4.0-32B를 실제 파이프라인에 포함시켜 추론에 활용할 수 있었습니다.
# 1. GGUF 양자화 모델 다운로드
python -c "
from huggingface_hub import hf_hub_download
hf_hub_download(
repo_id='LGAI-EXAONE/EXAONE-4.0-32B-GGUF',
filename='EXAONE-4.0-32B-Q4_K_M.gguf',
local_dir='./models',
local_dir_use_symlinks=False
)
"
# 2. llama.cpp CUDA 빌드
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
rm -rf build
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release -j 6
# 3. EXAONE 4.0 32B 서버 실행
./llama.cpp/build/bin/llama-server \
-m ./models/EXAONE-4.0-32B-Q5_K_M.gguf \
-c 32768 \
-np 4 \
-ngl 20 \
-fa on \
--ctx-size 32768 \
--port 8000 \
--host 0.0.0.0
주요 인자 설명 및 설정 근거:
| 인자 | 값 | 설명 |
|---|---|---|
-m | EXAONE-4.0-32B-Q5_K_M.gguf | 로드할 GGUF 모델 파일 경로 |
-c / --ctx-size | 32768 | context window 크기 (토큰 수) |
-ngl | 20 | GPU에 오프로드할 모델 레이어 수. 나머지는 CPU에서 처리 |
-np | 4 | 동시 처리 가능한 요청 수 (parallel slots) |
-fa | on | Flash Attention 활성화 |
--port / --host | 8000 / 0.0.0.0 | 서버 포트 및 바인딩 주소 |
-ngl 20은 OOM 없이 서버가 뜨는 것을 확인한 값으로, 체계적인 탐색 없이 대략적으로 설정한 수치였습니다.-np 4는 3가지 모드를 병렬로 요청할 수 있도록 넉넉하게 잡은 값입니다.- 서버가 실행되면
localhost:8000에서 OpenAI 호환 API로 접근 가능하여, 코드에서AsyncOpenAI(base_url="http://localhost:8000")로 바로 연결할 수 있습니다.
솔직히 말하면, 이 설정들은 “최적화된 설정”이라기 보다 “일단 안정적으로 돌아가는 조합”에 가까웠습니다. 당시에는 llama.cpp를 처음 사용하는 상황이었기 때문에, 서버가 OOM 없이 뜨고 추론이 정상적으로 수행되는지 확인하는 데 집중했습니다.
최적화?
총 VRAM ≈ 모델 가중치(ngl에 비례) + KV cache(np × context_size에 비례)
-ngl을 높이면 GPU에 올라가는 모델 레이어가 많아져 추론 속도가 빨라지지만, 그만큼 KV cache에 쓸 VRAM 여유가 줄어들어 -np나 -c를 낮춰야 합니다. 반대로 -np를 높이면 병렬 처리량은 늘지만 모델 레이어에 쓸 공간이 줄어듭니다.
이 관계를 당시에 알았다면, 예를 들어 -ngl을 30~40으로 올리고 -np를 2로 줄여서 개별 추론 속도를 높이는 방식이나, context window를 실제 입력 길이에 맞춰 16384 정도로 줄여 전체적으로 VRAM 여유를 확보하는 방식 등을 시도해볼 수 있을 것 같습니다.
이번 경험을 통해, 인프라 레벨의 설정이 단순히 실행 여부를 넘어 추론 비용과 처리 속도에 직접적인 영향을 준다는 점을 체감할 수 있었습니다. 다음에 llama.cpp를 사용할 일이 있다면, 조합별 벤치마크(추론 속도, VRAM 사용량, 처리량)를 먼저 측정한 뒤 설정을 잡는 방식으로 접근하면 더 좋을 것 같습니다.
Provider 고도화: DAPT
추가적으로 Provider 역할을 맡는 sktAX-Light 모델에는 fine-tuning도 고려할 수 있었으나, 데이터셋 구축을 위한 시간이 충분하기 않았기 때문에 DAPT(Domain-Adaptive Pretraining)만 적용했습니다.
목적은 모델이 국어 및 사회 영역의 지문과 해설에 자주 등장하는 서술 방식에 익숙해지도록 만드는 것이었습니다. 이를 위해 DAPT 데이터셋은 지문, 선택지, 해설 중심으로 구성 하였고, 문제 문항(question) 자체는 의도적으로 제외했습니다.
이렇게 한 이유는 모델이 정답을 직접 맞히는 능력을 키우기보다, 지문과 해설의 표현 방식에 적응해 더 유용한 분석 정보(description)를 생성하도록 유도하기 위해서 였습니다.
# src/dapt/dataset.py — DAPT 데이터 로드 및 전처리
def load_dapt_data(file_path: str) -> pd.DataFrame:
"""AIHub 국어 지문형 문제 데이터를 DAPT 학습용으로 로드·전처리"""
df = pd.read_csv(file_path)
records = []
for _, row in track(df.iterrows(), description="Processing samples...", total=len(df)):
problems = literal_eval(row['problems'])
parts = []
if pd.notna(row['paragraph']):
parts.append(f"[지문]\n{row['paragraph'].strip()}")
choices = problems.get('choices', [])
if choices:
formatted = '\n'.join([f"{i}. {c}" for i, c in enumerate(choices, 1)])
parts.append(f"\n[선택지]\n{formatted}")
if pd.notna(row.get('description')):
parts.append(f"\n[해설]\n{row['description'].strip()}")
records.append({'id': row['id'], 'text': '\n'.join(parts)})
return pd.DataFrame(records)
def _tokenize_dapt(examples, tokenizer, max_length):
"""Causal LM용 토크나이징 — labels를 input_ids와 동일하게 설정"""
tokenized = tokenizer(examples['text'], truncation=True, max_length=max_length, padding=False)
tokenized['labels'] = tokenized['input_ids'].copy()
return tokenized
DAPT 데이터를 구성하는 코드의 핵심은 다음과 같습니다.
- 지문·선택지·해설을
[지문],[선택지],[해설]태그로 구분하여 하나의 연속 텍스트로 결합 - 문제(question)는 의도적으로 제외하여, “정답 풀이”가 아니라 “서술 방식 적응”에 집중
labels = input_ids로 설정하여 Causal LM의 next-token prediction 방식으로 DAPT 학습을 진행- 최종적인 목표는 Provider 모델이 도메인 특유의 문체와 전개 방식에 보다 익숙해지는 것
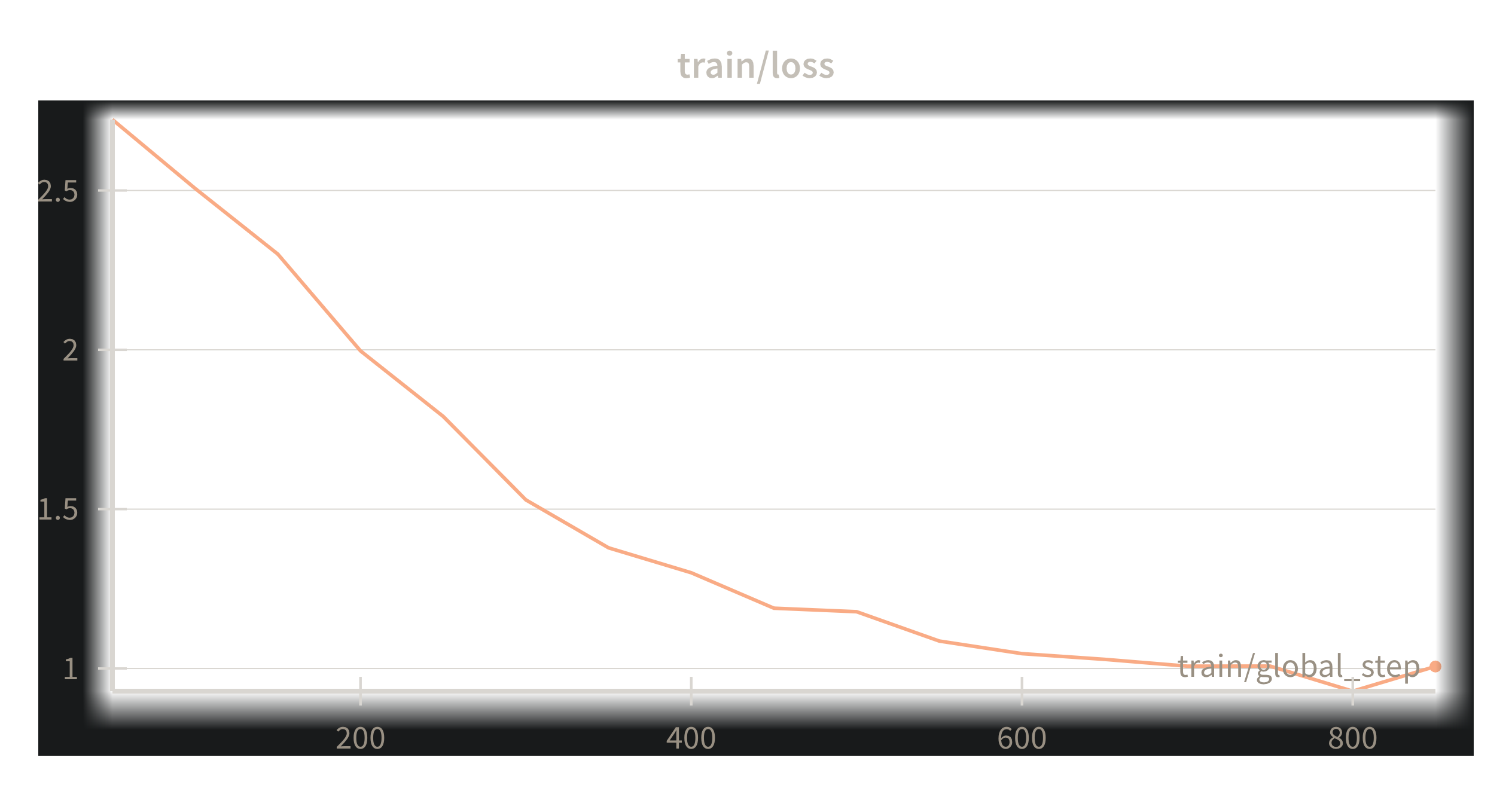
- dapt train loss 설명

- dapt 적용 및 프롬프트 최적화 이후 출력
MoA 파이프라인 구현
구현 과정
처음에는 Provider가 분석 정보를 생성하고, 이후 Aggregator가 이를 참고해 최종 답을 고르는 기본 구조를 만드는데 집중했습니다. 이후에는 프롬프트 조정, 다중 모드 추론, 다수결 로직 추가, 설정 관리 개선 순으로 점진적으로 고도화하였습니다.
파이프라인 구조
전체 파이프라인은 아래와 같은 흐름으로 구성하였습니다.
[문제 (지문 + 선택지)]
│
skt/A.X-Light (Provider)
├─ temp=0.3 → description_1 (분석적 관점)
└─ temp=0.7 → description_2 (탐색적 관점)
│
[descriptions → JSON으로 저장]
│
EXAONE-4.0-32B (Aggregator) × 3가지 모드
├─ (1) EXAONE만 (reasoning, descriptions 없이)
├─ (2) EXAONE + descriptions (reasoning 모드)
└─ (3) EXAONE + descriptions (non-reasoning 모드)
│
[3개 결과 다수결 → 최종 답]
문제와 지문, 선택지가 입력되었을 때, Provider는 문제의 정답을 생성하는 것이 아니라 문제를 바라보는 관점과 힌트를 생성합니다. 이후에 Aggregator가 초기 입력이랑 provider의 출력물을 함께 참고하여 최종 판단을 내리도록 설계하였습니다.
Provider: Description 생성 로직
Provider(sktAX-Light)는 문제를 직접 푸는 모델이라기보다 문제를 바라보는 관점과 힌트를 생성하고, Aggregator에게 전달할 분석 정보(description)를 만드는 역할을 맡았습니다.
Provider 모델의 프롬프트는 여러 시행착오를 거쳐 최종적으로 결정되었습니다.
- 처음에는 문제를 직접 풀도록 지시 → 정확도가 낮아서 비효율적
- 지문 + 선택지만 제공하고 요약과 관점 제시로 역할 변경
- 다음 추론 모델에 도움이 될 정보와 관점을 제공하도록 프롬프트 수정
- 파라미터 수정으로 불필요한 반복 제거, 출력 길이 제한
# src/inference/description_prompt.py — Provider 프롬프트
SYSTEM_PROMPT_DESCRIPTION = """당신은 국어 문제 해결을 돕는 분석 보조자입니다.
다음 모델이 문제를 풀 때 참고할 수 있는 **관점과 핵심 정보**를 제공하세요.
**역할:**
- 지문과 선택지를 연결하는 핵심 정보 제시
- 각 선택지 검토 시 고려해야 할 관점 제공
- 판단 근거가 될 정보만 제공
- 정답 언급 금지!
**출력 제한:**
- 100자 이내로 간결하게 작성
- 지문에 명시된 내용만 사용
- "정답은 X번", "X번이 맞다" 같은 직접적 답 제시 금지
- 불필요한 반복이나 장황한 설명 금지
"""
def format_description_prompt_no_plus(paragraph, question, choices):
"""<보기>가 없는 일반 문제용 프롬프트"""
formatted_choices = '\n'.join([f"{i}. {c}" for i, c in enumerate(choices, 1)])
return f"""[지문]
{paragraph}
[선택지]
{formatted_choices}
**작업:**
선택지를 판단하는 데 필요한 지문 속 핵심 정보를 간결하게 제시하세요.
- 각 선택지와 관련된 지문 내용을 1-2문장으로 요약
- 직접 답을 말하지 말고 판단 근거가 될 정보만 제공
- 총 100자 이내로 간결하게
"""
- system 프롬프트에서 “분석 보조자”로 역할을 한정하고, 정답 직접 언급을 명시적으로 금지
- 출력 길이를 100자 이내로 제한하여 Aggregator에 전달할 때 노이즈를 최소화
<보기>(question_plus) 유무에 따라 프롬프트 템플릿을 분기 처리
이 프롬프트를 사용하여 description을 생성하는 핵심 코드는 다음과 같습니다.
# src/inference/generate_description.py
def generate_description_single(
model, tokenizer, paragraph, question, choices,
question_plus=None, max_new_tokens=500,
temperature=0.7, top_p=0.9, repetition_penalty=1.1,
):
"""단일 문제에 대해 분석 정보(description)를 생성"""
user_prompt = get_prompt_template(
paragraph=paragraph, question=question,
choices=choices, question_plus=question_plus,
)
messages = [
{"role": "system", "content": SYSTEM_PROMPT_DESCRIPTION},
{"role": "user", "content": user_prompt},
]
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, ...)
outputs = model.generate(input_ids, max_new_tokens=max_new_tokens,
temperature=temperature, repetition_penalty=repetition_penalty, ...)
return tokenizer.decode(outputs[0][len(input_ids[0]):], skip_special_tokens=True)
- Provider는 문제를 직접 풀기보다 지문과 선택지에 대한 관점과 힌트를 생성하도록 하였고, temperature를 다르게 설정(0.3/0.7)해 동일 문제에 대해 2개의 description을 생성함으로써 다각도의 관점을 확보했습니다. 또한,
repetition_penalty=1.1을 적용해 불필요한 반복 출력도 억제하였습니다.
Aggregator: 3가지 모드 추론 + 다수결
Aggregator(EXAONE-4.0-32B)는 llama.cpp 서버를 통해 3가지 모드로 추론하고, 다수결로 최종 답을 결정합니다.
# inference_exaone.py — 3가지 모드 추론 + 다수결 선택
# 모드 1: EXAONE만 (reasoning, descriptions 없이)
user_content_1 = create_user_prompt_basic(paragraph, question, choices, question_plus)
tasks.append(get_inference(client, SYSTEM_PROMPT_BASIC, user_content_1, seed, cfg))
# 모드 2: EXAONE + descriptions (reasoning 모드)
user_content_2 = create_user_prompt_with_descriptions(
paragraph, question, choices,
description_1=desc_data.get("description_1", ""),
description_2=desc_data.get("description_2", ""),
)
tasks.append(get_inference(client, SYSTEM_PROMPT_MOA, user_content_2, seed, cfg))
# 모드 3: EXAONE + descriptions (non-reasoning 모드)
tasks.append(get_inference(client, SYSTEM_PROMPT_MOA_NO_REASONING, user_content_3, seed, cfg))
# --- 다수결로 최종 정답 선택 ---
count_choices = Counter(list_choice)
top_choices = count_choices.most_common(2)
if len(count_choices) == 3:
# 1:1:1 동점 → priority mode(reasoning + descriptions) 우선
answer = priority_mode or top_choices[0][0]
elif top_choices[0][1] == top_choices[1][1]:
# 1:1 동점 → priority mode가 동점 후보에 있으면 해당 답 선택
answer = priority_mode if priority_mode in [t[0] for t in top_choices] else top_choices[0][0]
else:
# 과반수 → 가장 많이 선택된 답
answer = top_choices[0][0]
이 구조의 핵심은 서로 다른 추론 경로를 병렬로 실행해, 각 모드가 내린 판단을 최종적으로 종합하는데 있습니다.
- 3가지 모드를 병렬로 추론: (1) EXAONE 단독, (2) Provider의 descriptions + reasoning, (3) Provider의 descriptions + non-reasoning
- 다수결(majority vote)로 최종 답을 선택, 동점 시에는 reasoning + descriptions 모드를 우선시하는 tie-break 로직 적용
- 각 모드별 정답과 reasoning_content를 함께 저장하여, 이후 분석 및 디버깅에 활용
실험 결과
전체 테스트 세트에 대해 파이프라인을 적용하기에는 시간이 부족했기 때문에, 기존에 다른 팀원들이 진행한 앙상블 결과 중 모델 간 예측이 크게 갈렸던 문제들만 선별하여 적용했습니다(Selective Inference).
모든 문제에 일괄적으로 적용하는 추론을 못하는 상황이라 아쉽지만, 추가 추론을 진행했을 당시 효과가 클 것으로 예상되는 문제에만 적용하는 방식으로 최선의 효과를 얻고자 하였습니다.
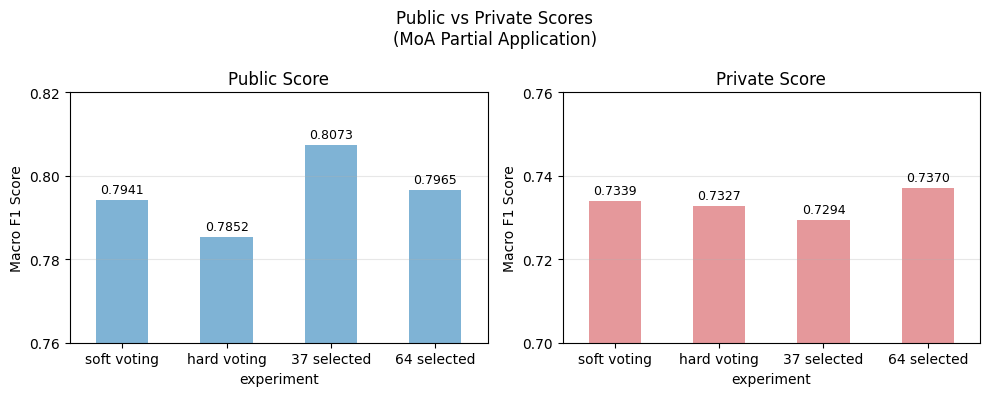
| 설정 | Public | Private |
|---|---|---|
| soft voting (baseline) | 0.7941 | 0.7339 |
| hard voting | 0.7852 | 0.7327 |
| MoA 37 selected | 0.7965 | 0.7294 |
| MoA 64 selected | 0.8073 | 0.7370 |
결과적으로 다음과 같은 점을 확인할 수 있었습니다.
- Public/Private 모두에서 MoA 64 selected가 최고 성능을 기록했습니다.
- 단순 soft/hard voting 대비 MoA를 선택적으로 적용한 것도 효과적이었음을 확인할 수 있었습니다.
- 모델 간의 역할 분담(Role-playing)을 통해 복잡한 문제를 해결할 수 있는 가능성도 확인할 수 있었습니다.
마무리
이번 실험에서 완전한 형태의 MoA를 구현한 것은 아니었지만, 주어진 제약 안에서도 역할을 분리한 추론 구조를 설계하고 실제로 동작하는 파이프라인으로 구현해보았다는 점에서 의미가 있었던 것 같습니다. 특히, 단일 대형 모델만 사용하는 방식에서 한 걸음 나아가 Provider와 Aggregator의 역할을 나누고 서로 다른 관점을 종합하는 방식이 일부 문제에서 성능 개선으로 이어질 수 있음을 확인할 수 있었습니다.
또한, 모델 자체 성능뿐 아니라, 프롬프트 설계, 추론 경로 구성, 서버 인프라 설정과 같은 요소들도 최종 결과 및 비용 측면에서 많은 영향을 준다는 것을 다시 체감할 수 있었습니다.
전체 데이터셋에 대한 일괄 적용이나 설정 최적화, 선택 기준의 정교화 같은 과제들이 남아 있지만, 제한된 자원 환경과 시간속에서 구조적 설계를 통한 문제해결 경험을 해본 점에서 의미있는 프로젝트였던 것 같습니다.