[FanMate] 페어프로그래밍으로 LangChain Agent 바닥부터 만들기 — 0.3에서 1.0으로, 달라진 것들
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
배경 — 왜 페어프로그래밍을 선택했는가
AI 코딩 도구가 빠르게 발전하고 있고, 실무에서도 적극적으로 활용되는 시대입니다. Cursor, Claude Code 같은 도구를 이용하면 꽤 빠른 속도로 쉽게 코드를 만들어낼 수 있습니다.
이러한 상황 속에서 프로젝트를 시작하면서 가졌던 마음은 코드를 얼마나 빠르고 쉽게 만들어내느냐가 아니라 코드를 잘 이해하고 내가 통제할 수 있어야한다였습니다. AI가 생성한 코드가 왜 그렇게 동작하는지 이해하지 못한다면, 문제가 생겼을 때 대응하기 어렵고, 결과적으로 코드 품질도 흔들릴 수 밖에 없다고 생각합니다.
또한, 이번 프로젝트에서는 기능 구현 만큼이나 어떤 기준으로 함께 개발할 것인가를 중요하게 생각했습니다. AI가 코드를 빠르게 만들어주는 시대일수록, 결과물만 맞추는 것보다 팀이 같은 맥락을 공유하고 코드의 동작을 함께 이해할 수 있는 방식으로 쌓아가는 것이 더 중요하다고 생각했습니다.
그래서 핵심 에이전트를 구현하는 단계에서는 작업을 잘게 나눠 각자 구현한 뒤 합치는 방식보다, 화면을 공유하고 같이 설계 및 구현을 하는 페어프로그래밍을 했습니다. 공식 문서를 함께 읽고, 저희가 이해한 범위 안에서 기능을 쪼개 쌓아가며, AI가 생성한 코드도 무비판적으로 받아들이지 않고 검증하는 방식으로 작업하기 위해서 페어프로그래밍을 선택했습니다.
초기 에이전트 구조는 이후 기능이 계속 덧붙는 기반이자, 전체 흐름을 떠받치는 뼈대에 가까운 영역이라고 생각했습니다. 한 번 방향이 잘못 잡히면 이후에 Memory, Tool, RAG 같은 기능을 추가할수록 구조를 되돌리기 어려워질 수 있기 때문에, 이 단계만큼은 빠르게 만들어내는 것보다 구조와 동작을 실제로 이해한 상태에서 출발하는 것이 더 중요하다고 생각했습니다. 적어도 팀 안에 최소 한 명, 가능하면 그 이상이 이 구조의 흐름과 핵심 기능을 설명하고 수정할 수 있어야 이후 확장과 트러블슈팅도 안정적으로 이어갈 수 있다고 생각했습니다.
작업 과정에서는 다음과 같은 기준을 두고 진행했습니다.
- 작업의 기준을 공식 문서로 한다.
- 작업 전날 관련된 기능의 공식 문서(LangChain, FastAPI 등)로 먼저 공부해온다.
- 이해한 내용을 바탕으로 직접 작성하거나, AI가 생성한 코드를 검증한다.
- 불필요한 코드가 들어가 있지는 않은지, 요구사항과 설계 의도에 맞는지 함께 확인한다.
- 처음부터 한꺼번에 완성하려 하지 않고, 기능을 쪼개 단계적으로 쌓는다.
- 기본 Agent → Memory → Summarization → Tool 순서로 작은 단위부터 동작을 확인하며 확장한다.
요즘 기준으로 보면 다소 느린 방식일 수 있습니다. 그래도 공부와 구현을 동시에 하는 입장에서는 꼭 필요한 과정이라고 생각했습니다. 실제로도 하나씩 동작을 확인하며 쌓아 올렸기 때문에, 구현 과정에서 코드의 흐름을 놓치지 않을 수 있었고, 문제가 생겨도 어느 레이어에서 발생했는지 비교적 빠르게 좁혀갈 수 있었던 것 같습니다.
LangChain 0.3에서 1.0으로 — 달라진 것들
이전 AINFO 프로젝트에서 LangChain 0.3을 사용한 경험이 있었는데, 1.0으로 넘어오면서 구조적으로 체감되는 변화가 꽤 컸습니다.
1. 에이전트 생성: AgentExecutor → create_agent
0.3에서는 에이전트 정의와 실행이 분리되어 있었습니다.
from langchain.agents import AgentExecutor, create_react_agent
agent = create_react_agent(llm, tools, prompt)
executor = AgentExecutor(agent=agent, tools=tools)
result = executor.invoke({"input": "안녕"})
1.0에서는 create_agent 하나로 통합되었습니다.
from langchain.agents import create_agent
agent = create_agent(
model=model,
tools=tools,
checkpointer=checkpointer,
middleware=[...],
)
result = await agent.ainvoke({"messages": [HumanMessage(content="안녕")]})
create_agent가 반환하는 객체 자체가 실행 가능합니다.- 이전에
AgentExecutor가 담당하던 도구 실행, 반복 루프, 에러 핸들링이 모두 내부로 흡수되었습니다.
2. 체인 → LCEL, 그리고 미들웨어
0.3에서는 LLMChain, ConversationalChain 같은 체인 클래스를 조합하는 방식이었습니다. 1.0에서는 간단한 파이프라인은 LCEL(LangChain Expression Language)로, 횡단 관심사(cross-cutting concern)는 미들웨어로 처리하는 구조로 바뀌었습니다.
agent = create_agent(
model=model,
tools=tools,
middleware=[
SummarizationMiddleware(trigger=("tokens", 3000), keep=("messages", 6)),
PIIMiddleware("email", strategy="redact"),
],
)
- 콜백 핸들러를 개별적으로 붙이던 방식에서, 선언적으로 미들웨어 리스트를 넘기는 방식으로 바뀌었습니다.
- 요약, PII 마스킹, 라우팅 같은 기능을 미들웨어로 깔끔하게 분리할 수 있어 에이전트 코드가 훨씬 단정해졌습니다.
LangGraph 호환성 증가
create_agent는 내부적으로 LangGraph의 StateGraph를 사용합니다.
- LangGraph가 별도 라이브러리에서 LangChain 에이전트의 기본 백본이 된 셈입니다.
- 덕분에 체크포인터, 상태 관리,
astream같은 기능을 그대로 활용할 수 있습니다. - 0.3에서는
ConversationBufferMemory를 직접 관리하고 상태 영속화를 별도로 구현해야 했기 때문에, 이 부분이 특히 인상적이었습니다.
단계별 에이전트 구현
1. 기본 Agent 만들기 — CLOVA Studio 연동
가장 먼저 한 일은, 최소한의 대화가 가능한 에이전트를 만드는 것이었습니다. langchain-naver의 ChatClovaX가 BaseChatModel을 구현하고 있어 create_agent에 바로 연결할 수 있었습니다.
from langchain_naver import ChatClovaX
from langchain.agents import create_agent
model = ChatClovaX(
model="HCX-DASH-001",
temperature=0.7,
max_tokens=1024,
api_key=settings.CLOVASTUDIO_API_KEY,
)
agent = create_agent(model=model, tools=[])
이 단계에서는 tool도 없고 memory도 없는, 말 그대로 질문-답변 수준의 가장 단순한 에이전트였습니다. 이후 LLM 연결이 정상적인지, 응답이 잘 들어오는지, 토큰 소모 확인 등 기본적인 검증도 진행하였습니다. 개인적으로는 이 시기는 변화된 LangChain을 학습하고 적응하는 기간이었던 것 같습니다.
스트리밍은 FastAPI의 StreamingResponse와 SSE를 조합해 구현했습니다.
@router.post("/chat")
async def chat(request: ChatRequest):
return StreamingResponse(
generate_response(request.message, request.user_id),
media_type="text/event-stream",
)
async def generate_response(message: str, user_id: str):
async for msg, metadata in agent.astream(
{"messages": [HumanMessage(content=message)]},
config=config,
stream_mode="messages",
):
if isinstance(msg, AIMessage) and msg.content:
yield f"data: {msg.content}\n\n"
agent.astream()이stream_mode="messages"로 토큰 단위 스트리밍을 네이티브로 지원합니다.
2. Memory 붙이기 — PostgreSQL Checkpointer
기본 에이전트 동작을 확인한 뒤에는 메모리를 연결했습니다. 0.3에서는 ConversationBufferMemory 과 같은 메모리 객체를 직접 붙이는 방식이었다면, 1.0에서는 LangGraph의 체크포인터를 사용하는 방식으로 바뀌었습니다.
from langgraph.checkpoint.postgres.aio import AsyncPostgresSaver
async with AsyncPostgresSaver.from_conn_string(
conn_string=settings.DB_URI
) as checkpointer:
await checkpointer.setup()
agent = create_agent(
model=model,
tools=tools,
checkpointer=checkpointer,
)
checkpointer를 넘기면 에이전트의 모든 상태 변화가 자동으로 PostgreSQL에 저장됩니다.thread_id만 지정하면 이전 대화를 그대로 이어갈 수 있습니다.
config = {"configurable": {"thread_id": f"{session_id}_{user_id}"}}
async for msg, metadata in agent.astream(
{"messages": [HumanMessage(content="어제 경기 결과 알려줘")]},
config=config,
stream_mode="messages",
):
...
별도 메모리 클래스를 선택하고 초기화하고 체인에 끼워넣는 과정이 필요했는데, 1.0에서는 이런 부분이 많이 단순해졌습니다.
처음에는 이전 프로젝트에서 Redis를 이용해 메모리를 다뤄본 경험 때문에, 이번에도 체크포인터 저장소로 Redis를 우선 떠올렸습니다. 인메모리 저장소 특성상 대화 이력의 읽기/쓰기에 유리할 것이라 생각했기 때문입니다.
하지만, LangGraph 공식 문서의 체크포인터 튜토리얼이 PostgreSQL 기반으로 작성되어 있었습니다. 공식 문서의 예제를 직접 따라가면서 체크포인터 시스템이 내부적으로 어떻게 동작하는지 이해하는 것이 우선이었기 때문에 PostgreSQL로 먼저 구현하고, 나중에 Redis 저장소로 바꿀 계획이었습니다.
3. Summarization Middleware 붙이기
메모리를 붙인 뒤에는 대화가 길어질 때를 대비해 요약 기능을 추가하기로 했습니다. 길어진 대화는 컨텍스트 윈도우를 빠르게 소모하고, 불필요한 이전 메시지가 응답 품질에도 영향을 줄 수 있기 때문입니다.
0.3에서는 ConversationSummaryMemory라는 별도 메모리 타입으로 접근했다면, 1.0에서는 SummarizationMiddleware로 처리할 수 있었습니다.
from langchain.middleware import SummarizationMiddleware
agent = create_agent(
model=model,
tools=tools,
checkpointer=checkpointer,
middleware=[
SummarizationMiddleware(
model=model,
trigger=("tokens", 3000),
keep=("messages", 6),
summary_prompt="다음 대화를 한국어로 간결하게 요약하세요:\n{messages}",
),
],
)
trigger=("tokens", 3000): 메시지 토큰 합이 3000을 넘으면 요약을 실행합니다.keep=("messages", 6): 최근 6개 메시지는 원본을 유지하고, 나머지를 요약합니다.
keep 값을 6으로 설정한 것은 서비스 시나리오를 기반으로 판단한 결과입니다. 영업왕 챗봇의 주요 흐름은 대체로 “팀 소개 요청” → “세부 정보 질문” → 후속 질문” 정도였기 때문에, 직전 및 몇 개의 상호작용만 살아 있으면 맥락을 유지하는 데 충분하다고 생각했습니다. 그보다 앞선 대화는 요약본으로 압축해도 응답 품질에 큰 영향을 주지 않았고, 오히려 맥락이 정리되면서 답변의 초점이 더 선명해지는 경우도 있었습니다.
5. Redis vs PostgreSQL — 벤치마크로 판단하기
요약 기능을 추가하고 나니, 실제로 체크포인터에 저장, 조회되는 메시지 양이 생각보다 크지 않았습니다. 그러다 보니 Redis가 PostgreSQL보다 확실히 유리하다고 단정하기 어려워서 직접 비교를 해보기로 했습니다.
Docker Compose에 Redis Stack을 추가하고, langgraph-checkpoint-redis 의존성을 연결한 뒤 TTFT 중심으로 벤치마크를 수행했습니다.
LLM 응답 지연과 Checkpoint I/O 지연을 분리 측정하기 위해 CheckpointIOTracker를 만들어 aget_tuple과 aput 호출 시간을 따로 측정했고, SummarizationMiddleware가 실제로 동작하는 멀티턴 상황까지 포함해 테스트했습니다.
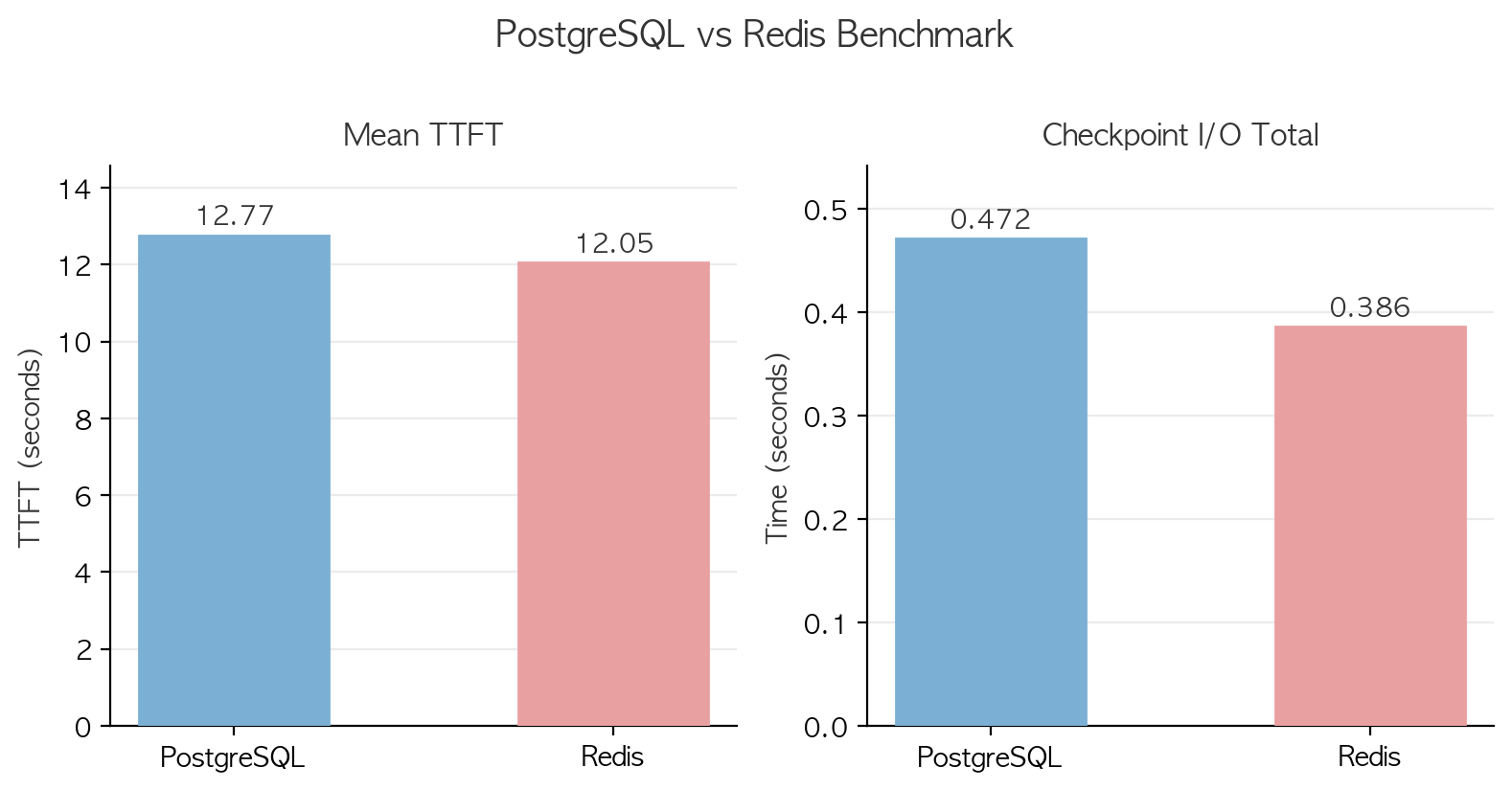
| 항목 | PostgreSQL | Redis | 차이 |
|---|---|---|---|
| TTFT 평균 | 12.77s | 12.05s | 0.72s |
| Checkpoint I/O 총합 (12턴) | 0.472s | 0.396s | 0.08s |
- TTFT 차이 0.72초는 LLM API 호출 자체의 편차 범위 내였습니다.
- Checkpoint I/O만 분리해서 보면 PostgreSQL 0.47초, Redis 0.39초로, 전체 응답 시간에서 I/O가 차지하는 비중이 3~4%에 불과했습니다.
SummarizationMiddleware가 오래된 대화를 요약본으로 압축하기 때문에, 체크포인터에서 실제로 불러오는 메시지 수가 적어 저장소의 읽기 속도 차이가 체감되기 어려웠습니다.
결국 성능상 이점이 뚜렷하지 않은 상황에서 Redis를 추가로 운영하는 것은 인프라 복잡도만 늘리는 선택이라고 판단했습니다. 따라서, 체크포인터는 PostgreSQL로 유지했습니다.
6. Tool 연동 — 네이버 검색 API
기존 에이전트에 memory와 summarization 까지 붙이고 나니, 이제는 외부 정보를 가져오는 기능을 붙여야했습니다. 영업왕 챗봇은 최신 KBO 뉴스나 실시간 순위처럼 시점이 민감한 정보도 다뤄야했기 때문에 외부 검색 기능을 필수였습니다.
검색 기능으로는 Tavily와 네이버 검색 API 중에서 KBO의 정보를 더 잘 가져올 수 있는 네이버 검색 API를 사용하였고, LangChain의 @tool 데코레이터로 감싸 에이전트에 연결했습니다.
from langchain_core.tools import tool
@tool("naver_web_search")
def naver_web_search(query: str) -> str:
"""최신 KBO 뉴스, 실시간 순위 등 최신 정보를 검색할 때 사용합니다."""
news = requests.get(
"https://openapi.naver.com/v1/search/news.json",
headers={"X-Naver-Client-Id": ..., "X-Naver-Client-Secret": ...},
params={"query": query, "display": 5, "sort": "sim"},
)
# ... 결과 포매팅
return formatted_result
이 시점부터는 에이전트는 단순히 대화만 하는 모델이 아니라, 필요한 시점에 외부 정보를 조회하고 그 결과를 바탕으로 응답을 구성하는 구조를 갖추게 되었습니다.
이 시점에서의 아키텍처
1/28일 기준, 완성된 구조는 다음과 같았습니다.
FastAPI (SSE Streaming)
└── create_agent
├── model: ChatClovaX (CLOVA Studio)
├── tools: [naver_web_search]
├── checkpointer: AsyncPostgresSaver (PostgreSQL)
└── middleware: [SummarizationMiddleware]
기능적으로는 최소한이지만, 확장 가능한 뼈대가 갖춰진 상태였습니다. 이후에 RAG, SQL Agent, PII 보호, 라우팅, 톤 조정, 팀별 페르소나 등을 추가할 때, 이 구조 위에 도구와 미들웨어를 하나씩 끼워넣는 것만으로 대응할 수 있었습니다.
회고
페어프로그래밍으로 LangChain Agent를 만들면서 가장 크게 느낀 것은, 이해를 동반한 구현이 결국 빠르다는 점이었습니다.
처음부터 모든 기능을 한꺼번에 넣었다면, 구현은 더 빨라 보였을지 몰라도 구현한 기능에 대한 이해가 부족해서 이후 확장과 디버깅은 훨씬 어려웠을 것입니다. 이번에는 단계적으로 기본 Agent, Memory, Summarization, Tool 순서로 레이어를 나누고, 각 단계에서 실제로 무엇이 동작하는 지 확인하면서 쌓아올렸습니다. 그 덕분에 이후 기능을 추가하는 과정에서 문제가 생기더라도, 어디에서부터 원인을 확인해야 하는지 비교적 빠르게 좁혀나갈 수 있었습니다. 한 번에 모든 기능을 얹는 방식보다, 구조를 단계별로 분리해 이해하고 검증해 둔 것이 확장과 트러블슈팅 모두에 도움이 되었습니다.
LangChain 0.3에서 1.0으로의 변화도 직접 겪어보니 단순한 API변경 이상이었습니다. AgentExecutor와 여러 체인을 조합하던 방식에서 create_agent와 미들웨어 중심 구조로 넘어오면서, 에이전트를 직접 조립하는 느낌보다는 필요한 기능을 끼워넣는 구조로 바뀌었습니다. 이번 작업은 그 변화를 문서로만 읽는 것이 아닌, 실제 코드로 따라가며 체감해볼 수 있었던 과정이었습니다.