[FanMate] RAG 파이프라인 구축
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
배경
LLM은 기본적으로 학습된 지식에 의존해 답변을 생성합니다. 그래서 서비스에 바로 적용하려고 하면 두 가지 한계가 분명하게 드러납니다. 하나는 최신 정보를 반영하지 못한다는 점, 다른 하나는 서비스에 특화된 세부 정보를 충분히 알지 못한다는 점입니다. KBO 구단 정보 및 최신 뉴스 정보를 다루는 FanMate에서도 이 한계는 분명했습니다.
마스코트, 응원가, 하이라이트 같은 정형 데이터는 데이터베이스에 저장해 활용할 수 있었습니다. 하지만, 구단 역사, 선수 정보, 팬 문화처럼 길고 맥락이 중요한 비정형 텍스트 데이터 는 단순한 테이블 구조로 다루기 어려웠습니다. 이런 정보까지 자연스럽게 답변하려면, 사용자의 질문과 관련된 문서를 먼저 검색하고 그 결과를 바탕으로 답변을 생성하는 RAG(Retrieval-Augmented Generation) 구조가 필요했습니다.
그래서 이번 단계에서는 KBO 관련 문서를 벡터화해 저장하고, 런타임에서는 에이전트가 필요한 시점에 검색 도구를 호출해 참고 문서를 가져오도록 RAG 파이프라인을 구축했습니다.
전체 아키텍처
구축한 RAG 파이프라인의 전체 흐름은 다음과 같습니다.
문서 로드 (loader) → 청킹 (splitter) → 임베딩 + 저장 (vectorstore)
↓
사용자 질문 → 쿼리 분류 (routing) → rag_search 도구 호출 → 시멘틱 검색 (retriever) → LLM 답변 생성
오프라인 단계에서는 문서를 불러오고, 적절한 단위로 나눈 뒤, 임베딩을 생성해 ChromaDB에 저장했습니다. 런타임에서는 에이전트가 rag_search 도구를 호출하고, retriever가 관련 문서를 검색한 뒤, 그 결과를 바탕으로 답변을 생성하도록 구성하였습니다.
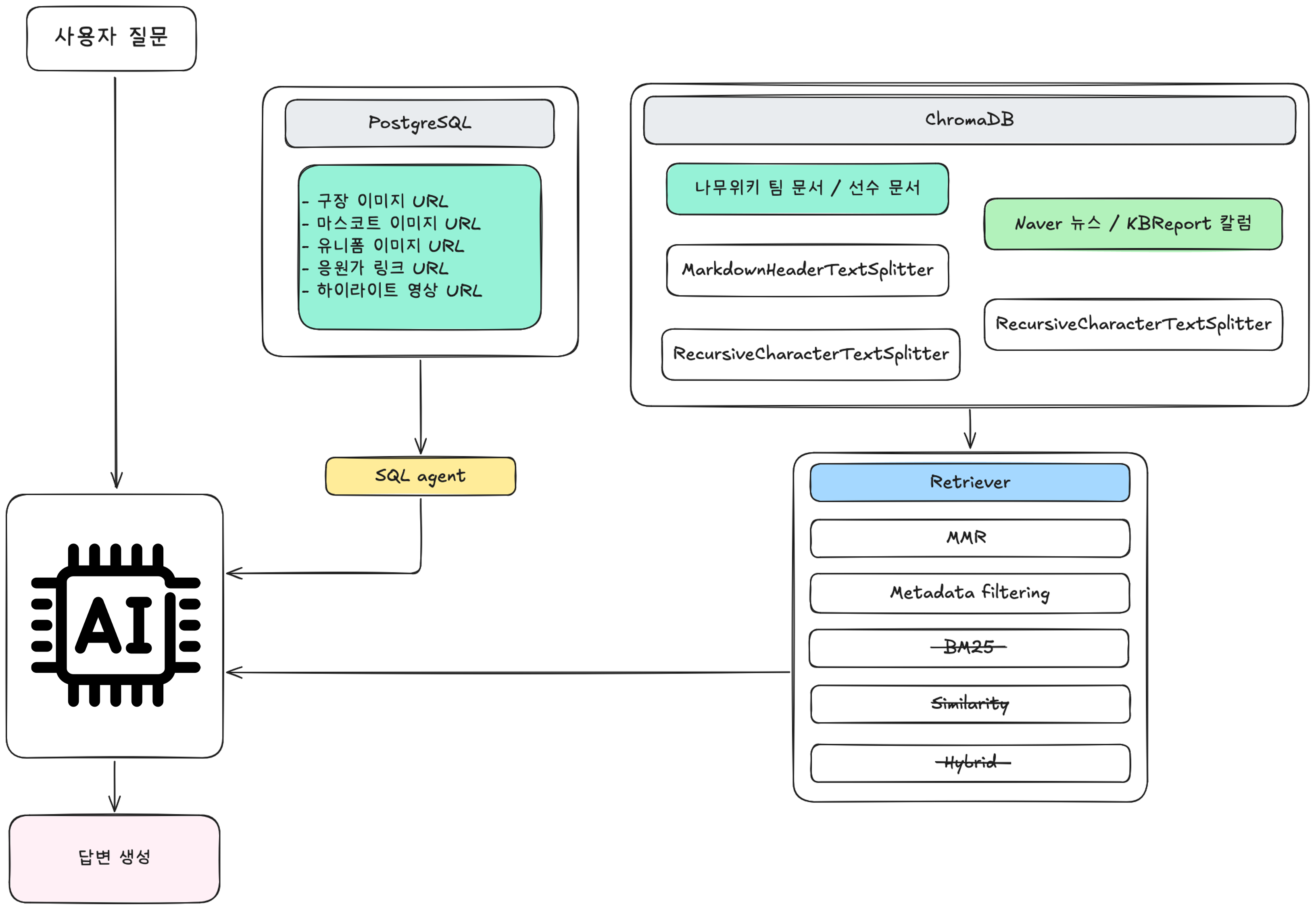
RAG는 영업왕뿐 아니라 다른 챗봇 서비스에서도 사용하기 때문에 common이라는 공통의 디렉토리로 따로 빼서 파일 구조를 구성하였습니다.
backend/app/services/common/rag/
├── loader.py # 문서 로드 (팀/선수/뉴스)
├── splitter.py # 2단계 청킹
├── vectorstore.py # ChromaDB + 임베딩 설정
└── retriever.py # 검색 (MMR + 메타데이터 필터)
backend/app/services/common/
└── tools.py # rag_search 도구 정의
backend/scripts/
└── build_vectordb.py # 벡터DB 빌드 스크립트
이러한 구조는 문서 수집부터 검색, 에이전트 통합, 실험 자동화까지 기능을 분리해 확장할 수 있게 되었습니다.
문서 로드 — 3가지 데이터 소스
초기에는 팀 문서만 대상으로 시작했지만, 리팩토링을 거치면서 팀 문서, 선수 문서, 뉴스 csv의 세 가지 소스를 통합했습니다.
1. 팀 문서
나무위키에서 크롤링한 KBO 10개 구단의 마크다운 파일입니다.
# backend/app/services/common/rag/loader.py
TEAM_MAP = {
"lg_twins": "LG",
"doosan_bears": "두산",
"kiwoom_heroes": "키움",
"ssg_landers": "SSG",
# ...
}
def load_team_documents(team_docs_dir, source=None, date=None):
for md_file in tqdm(docs_path.glob("*.md"), desc="팀 문서 로드 중..."):
text = md_file.read_text(encoding="utf-8")
team_code = TEAM_MAP.get(md_file.stem, md_file.stem)
doc = Document(
page_content=text,
metadata={
"team": team_code,
"source": source or extract_source_from_path(md_file),
"date": date or extract_date_from_path(md_file),
"file": md_file.name,
},
)
- 파일 이름을 기준으로 팀 코드를 매핑했습니다.
- 경로에서
source와date를 자동 추출하도록 했습니다. extract_date_from_path()는 경로에YYYY-MM-DD형식의 디렉토리가 있으면 해당 날짜를 사용하고, 없으면 오늘 날짜를 기본값으로 사용합니다.
2. 선수 문서
선수 문서는player/팀폴더/선수.md 구조로 저장되어 있었고, 팀별 디렉토리를 순회하며 개별 선수 문서를 불러오는 방식으로 처리했습니다.
3. 뉴스 CSV
KBO 관련 뉴스 기사를 CSV로 수집한 데이터입니다. 제목과 본문을 하나의 문서로 합치고, 검색 시 구분할 수 있도록 type: "news" 메타데이터를 부여했습니다.
def load_news_csv_documents(csv_file, source_type="news", source_name="kbreport"):
with open(csv_path, encoding="utf-8-sig") as f:
reader = csv.DictReader(f)
for row in tqdm(reader, desc="뉴스 CSV 로드 중..."):
page_content = f"# {row.get('제목', '')}\n\n{row.get('본문', '')}"
doc = Document(
page_content=page_content,
metadata={
"source": f"{source_type}/{source_name}",
"type": "news",
"url": row.get("URL", ""),
# ...
},
)
세 가지 소스를 분리해 로드한 이유는 메타데이터 구조가 서로 다르기 때문입니다. 팀 문서에는 team, 뉴스에는 url, 선수 문서에는 type: "player" 같은 정보가 포함되어 있고, 이후 검색 단계에서는 이런 메타데이터를 기준으로 필터링을 수행하게 됩니다.
2단계 청킹
나무위키 문서는 마크다운 헤더를 기준으로 비교적 잘 구조화되어 있습니다. 그래서 단순히 RecursiveCharacterTextSplitter만 사용하면 서로 다른 헤더의 내용이 하나의 청크에 섞일 수 있기 때문에, 먼저 헤더 기준으로 의미 단위를 나누고 길이 기준으로 다시 분할하는 2단계 청킹 방식이 더 적합하다고 판단했습니다.
# backend/app/services/common/rag/splitter.py
def split_documents(documents, chunk_size=800, chunk_overlap=150):
# 1단계: 마크다운 헤더 기준 분할
md_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=[
("#", "header_1"),
("##", "header_2"),
("###", "header_3"),
],
strip_headers=True,
)
# 2단계: 크기 기준 재분할
char_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
)
for doc in documents:
original_metadata = doc.metadata.copy()
header_splits = md_splitter.split_text(doc.page_content)
chunks = char_splitter.split_documents(header_splits)
for chunk in chunks:
chunk.metadata = {**original_metadata, **chunk.metadata}
- 1단계:
MarkdownHeaderTextSplitter로 헤더(#,##,###)를 기준으로 먼저 분할해 의미 단위를 보존합니다. - 2단계: 헤더 기준으로만 나누면 여전히 긴 구간이 남아 있을 수 있기 때문에,
RecursiveCharacterTextSplitter로 다시 잘라 청크 크기를 일정하게 맞춥니다. - 메타데이터 전파: 원본 문서의
team,source,date와 청킹 과정에서 추가된header_1~3정보를 모두 유지해, 이후 검색 결과를 더 잘 해석할 수 있도록 했습니다.
임베딩과 벡터 스토어
임베딩 모델은 OpenAI의 text-embedding-3-small을 사용했습니다.
# backend/app/services/common/rag/vectorstore.py
underlying_embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
api_key=settings.OPENAI_API_KEY,
)
cache_store = LocalFileStore(CACHE_DIR)
embeddings = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings,
cache_store,
namespace=underlying_embeddings.model,
)
- 동일한 텍스트에 대해 반복적으로 임베딩 API를 호출하는 비용을 줄이기 위해
CacheBackedEmbeddings를 적용했습니다. - 한 번 임베딩된 청크는 로컬 파일 시스템에 캐시되므로, 벡터DB를 다시 빌드할 때도 캐시를 재사용할 수 있습니다.
벡터 스토어는 ChromaDB를 선택했습니다.
def get_vector_store():
vector_store = Chroma(
collection_name="kbo_teams",
embedding_function=embeddings,
persist_directory="vectordb/chroma_data",
collection_metadata={"hnsw:space": "cosine"},
)
return vector_store
persist_directory를 지정하여 디스크에 영속 저장되도록 했습니다. 서버를 재시작해도 벡터DB가 유지됩니다.hnsw:space: "cosine"으로 코사인 유사도 기반의 HNSW 인덱스를 사용했습니다.- 모든 데이터를 하나의 컬렉션(
kbo_teams)에 저장하고, 메타데이터 필터링으로 팀 문서, 선수 문서, 뉴스를 구분했습니다.
ChromaDB를 선택한 이유는 별도 서버 없이 임베디드 모드로 실행할 수 있고, LangChain과의 통합이 간단했기 때문입니다. FanMate 규모에서는 Pinecone이나 Weaviate 같은 매니지드 벡터DB보다 더 적절한 선택이었습니다.
시멘틱 검색 — MMR과 메타데이터 필터링
검색 모듈에서 중요했던 설계 포인트 중 하나는 검색 방식 과 팀별 필터링 이었습니다.
# backend/app/services/common/rag/retriever.py
def search(query: str, team: str = None, k: int = 5):
vector_store = get_vector_store()
if team:
filter_dict = {
"$or": [
{"team": team},
{"type": "news"},
]
}
else:
filter_dict = None
retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={
"k": k,
"fetch_k": 50,
"filter": filter_dict,
"lambda_mult": 0.5,
},
)
return retriever.invoke(query)
초기 검색 방식으로 MMR(Maximal Marginal Relevance) 을 선택했습니다. 단순 유사도 검색은 비슷한 내용의 청크를 중복해서 반환하는 경향이 있는데, MMR은 관련성과 다양성을 함께 고려해 중복을 줄이는 데 도움이 된다고 판단했습니다.
초기 설정은 다음과 같았습니다:
fetch_k=50: 초기에 50개의 후보를 가져온 뒤k=5: MMR 알고리즘으로 최종 5개를 선별합니다lambda_mult=0.5: 관련성과 다양성의 비중을 1:1로 설정했습니다
또한 메타데이터 필터링을 함께 적용했습니다. 특정 팀이 지정되면 해당 팀 문서와 뉴스 문서를 함께 검색하고, 팀이 지정되지 않으면 전체 컬렉션을 대상으로 검색하도록 했습니다. 뉴스 문서에는 팀 메타데이터가 없는 경우가 있었기 때문에, {"team": team}와 {"type": "news"} 를 $or로 묶어 누락을 방지했습니다.
에이전트 도구 통합
RAG의 검색 기능을 에이전트가 사용할 수 있는 도구로도 연결하였습니다.
# backend/app/services/common/tools.py
@tool("rag_search")
def rag_search(query: str, team: str = "") -> str:
"""KBO 프로야구 10개 구단 관련 정보를 검색합니다.
다음과 같은 질문에 이 도구를 사용하세요:
- 구단 역사 및 연혁 (창단, 우승 기록, 역대 감독 등)
- 선수 정보 (현역/은퇴 선수, 기록, 수상 내역)
- 홈 구장 정보
- 응원가, 마스코트, 유니폼
- 팬 문화 및 별명
Args:
query: 검색할 질문 또는 키워드
team: 팀명 필터 (LG, 두산, SSG, KT, 키움, 한화, 삼성, 롯데, NC, KIA)
"""
results = rag_search_fn(query, team=team, k=5)
if not results:
return "관련 문서를 찾지 못했습니다"
formatted = []
for i, doc in enumerate(results, 1):
team_name = doc.metadata.get(team, team)
formatted.append(f"[{i}] ({team_name}) {doc.page_content}")
return "\n\n".join(formatted)
- LangChain의
@tool데코레이터로 정의하면 에이전트가 docstring을 바탕으로 해당 도구를 언제 호출해야 할지 판단합니다. - 따라서, docstring에 어떤 질문 유형에서 이 도구를 써야 하는지를 구체적으로 적어두었습니다.
- 검색 결과는
[1] (LG) 문서 내용...형식으로 포맷팅하여 LLM에 컨텍스트로 전달합니다. - 포맷팅을 하게 되면, 검색 결과가 단순한 텍스트 덩어리로 들어가는 것보다 에이전트가 문서 단위를 더 명확하게 인식할 수 있습니다.
벡터DB 빌드
오프라인에서 벡터DB를 구축하는 스크립트도 구현하였습니다.
# backend/scripts/build_vectordb.py
def build(docs_dir, source=None, date=None, batch_size=100):
# 1. 3가지 소스 로드
team_docs = load_team_documents(docs_dir / "team", source=source, date=date)
player_docs = load_player_documents(docs_dir / "player", source=source, date=date)
news_docs = load_news_csv_documents(csv_path)
all_documents = team_docs + player_docs + news_docs
# 2. 청킹
chunks = split_documents(all_documents)
# 3. 배치 임베딩 + ChromaDB 저장
vector_store = get_vector_store()
for i in tqdm(range(0, len(chunks), batch_size), desc="임베딩 저장 중..."):
batch = chunks[i : i + batch_size]
vector_store.add_documents(batch)
- 전체 청크를 한 번에 임베딩하면 메모리 사용량이 커질 수 있기 때문에,
batch_size=100단위로 나눠 저장하도록 했습니다. - 이후
BuildConfig를 도입해chunk_size와chunk_overlap조합별로 벡터DB를 일괄 생성할 수 있는--multi옵션도 추가했습니다. 이 기능은 다음 단계인 RAG 실험 자동화의 기반이 되었습니다.
🔄 회고
RAG를 구축하면서 가장 크게 배운 점은 좋은 RAG를 만드는 데에는 단순히 많은 정보와 문서를 쌓는 것만으로는 부족하다는 사실이었습니다. 물론 데이터 수집 자체도 어렵고 중요한 작업은 맞지만, 실제 구현 단계에서 더 중요한 것은 데이터를 얼마나 많이 확보했느냐보다 가지고 있는 데이터를 어떤 구조로 가공하고 검색 가능한 형태로 설계하느냐인 것 같습니다.
이전에도 RAG를 구현해봤었지만, 당시에는 개념 이해와 개발 경험이 모두 부족해 전체 흐름만 이해하고 세세한 디테일에 대한 생각은 많이 못했습니다. 반면, 이번에는 “그냥 VectorDB를 만든다”가 아니라 문서를 어떤 단위로 나눌지, 어떤 메타데이터를 유지할지, 어떤 검색 방식을 선택할지에 따라 검색 품질이 달라진다는 것을 배우고 고민하는 시간이었습니다. 또한, reranking 같은 후처리까지 고려해보면서 RAG는 단순히 검색 기능을 붙이는 것이 아니라 다양한 전략과 세밀한 판단이 필요한 영역임을 느끼고 많은 공부와 실험이 필요한 영역이라는 것을 체감했습니다.
한편, 제가 구현한 기능에서만 사용하는 것이 아니라 팀원들도 함께 쓸 수 있는 RAG를 구현하는 과정에서 구조 설계의 중요성도 느낄 수 있었습니다. 문서 로드, 청킹, 임베딩, 검색, 도구 연결 단계를 모듈화하고 공통 디렉토리로 분리해두면서, 특정 기능에 종속된 구현이 아니라 여러 서비스에서 재사용 가능한 기능으로 구현하였습니다.
이번 RAG 작업에서는 단순히 RAG를 한 번 구현한 경험이라기보다, 검색 품질과 확장성에 대해서 고민하는 시간과 구조를 설계하는 과정을 배운 시간이었습니다.