[FanMate] 멀티 페르소나 구현 — 체크포인터 상태 덮어쓰기로 대화방 만들기
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
배경
FanMate의 영업왕 챗봇은 KBO 10개 구단 각각의 “열정적인 팬” 페르소나로 응답합니다. 사용자가 LG를 선택하면 LG 팬으로, 삼성을 선택하면 삼성팬과 대화하는 구조입니다.
여기서 추가로 해결해야할 기획 요구사항이 있었습니다. 하나의 대화방 안에서 여러 팀의 팬(영업왕)이 번갈아 발언하는 구조 를 만들어야 했습니다. 예를 들어, 사용자가 LG 팬에게 질문한 뒤 삼성 팬에게 같은 질문을 하면, 삼성 팬은 LG 팬이 앞서 한 말을 인식을 하지만 자신이 출력한 말을 아니라는 것을 알고 반응을 해야 했습니다.
문제는 LangGraph의 체크포인터가 하나의 thread_id에 메시지를 순차적으로 쌓는 구조라는 점이었습니다. 이 상태로는 이전 응답이 어떤 팀의 페르소나에서 나온 것인지 구분할 수 없기 때문에, LLM도 여러 팀 팬이 같은 대화방에서 대화하고 있다는 맥락을 제대로 이해하기 어려웠습니다.
즉, 이 기능의 핵심은 단순히 팀별 페르소나를 바꾸는 것이 아니라, 하나의 대화 이력 안에서 “누가 한 말인지”를 LLM이 구분할 수 있게 만드는 것 이었습니다. 결국 멀티 페르소나 구현의 출발점은 대화 내용을 저장하는 것만으로는 부족하고 발화자 정보까지 함께 유지할 수 있는 구조를 만드는 데 있었습니다.
핵심 아이디어 — 메시지 태깅
구현을 위한 핵심 아이디어는 단순했습니다. AI 응답을 체크포인터에 저장할 때, 앞에 [팀이름 팬] 태그를 붙여 누가 말했는지 표시하는 방법이었습니다.
체크포인터에 저장되는 대화 이력:
HumanMessage: "LG 트윈스 역사 알려줘"
AIMessage: "[LG 팬] LG 트윈스는 1990년 창단된 팀으로..."
HumanMessage: "삼성은 어때?"
AIMessage: "[삼성 팬] 삼성 라이온즈는 한국시리즈 최다 우승팀이에요!"
HumanMessage: "둘 중에 어디가 더 좋아?"
AIMessage: "[LG 팬] 당연히 LG죠! 삼성 팬분이 우승 얘기 하셨는데..."
이렇게 저장해두면 LLM은 히스토리 안의 [LG 팬]과 [삼성 팬] 태그를 서로 다른 발화자로 인식할 수 있습니다. 현재 자신이 어떤 팀의 팬인지는 시스템 프롬프트에서 지정되므로, 다른 태그가 붙은 메시지는 자연스럽게 “다른 팀 팬의 발언”으로 해석하게 됩니다.
단, 문제는 LangGraph의 create_agent가 생성한 응답에 임의로 태그를 직접 붙이기 어렵다는 점이었습니다. 스트리밍(astream)이 끝나면 응답은 자동으로 체크포인터에 저장되는데, 이 시점에는 태그가 포함되지 않습니다.
체크포인터 상태 덮어쓰기 — aupdate_state
처음에는 출력물 앞에 태그를 붙이라는 프롬프트를 사용했는데, 처음에는 태그를 잘 붙이다가 2~3턴을 거치면 태그를 생략하는 경우가 많았습니다. 그 다음에는 출력 스트리밍의 첫 청크에 태그를 삽입하는 방식을 시도했습니다. 하지만 톤 조정 미들웨어를 거치며 태그가 유실되거나, 도구 호출이 끼어들며 타이밍이 어긋나는 문제가 발생했습니다.
그래서 최종적으로는 LangGraph의 aget_state / aupdate_state API를 활용해서 출력이 완전 끝난 후에 사후 덮어쓰기 방식 으로 전환했습니다.
# backend/app/services/sales/chat.py (핵심 로직)
tag = f"[{team_name} 팬] "
# 1단계: 에이전트 실행 — 원본 응답 수집
original_content = ""
async for msg, metadata in agent.astream(
{"messages": [HumanMessage(content=user_message)]},
config=config,
stream_mode="messages",
context={"team_name": team_name, "model": model, "routing_hint": query_type},
):
if isinstance(msg, AIMessage) and not msg.tool_calls:
if hasattr(msg, "content") and msg.content:
original_content += str(msg.content)
# 2단계: 톤 조정 후 스트리밍 출력
tone_adjusted_content = ""
async for token in stream_tone_adjusted_response(
original_content=original_content,
user_query=user_message,
team_name=team_name,
model=model,
):
tone_adjusted_content += token
yield token # 사용자에게 스트리밍
# 3단계: 체크포인터의 마지막 AIMessage를 태그 붙인 버전으로 교체
state = await agent.aget_state(config)
messages = state.values.get("messages", [])
if messages:
last_msg = messages[-1]
if isinstance(last_msg, AIMessage):
tagged_msg = AIMessage(
content=tag + final_content,
id=last_msg.id, # 같은 ID → replace 동작
)
await agent.aupdate_state(config, {"messages": [tagged_msg]})
aget_state()로 현재 체크포인터 상태를 조회해서 마지막AIMessage를 가져옵니다.- 동일한
id를 가진 새AIMessage를 만들어aupdate_state()로 넣습니다.
참고로 LangGraph의 add_messages reducer는 같은 ID의 메시지가 이미 존재하면 append가 아닌 replace로 동작합니다. 즉, 기존 응답을 지우고 태그가 포함된 버전으로 바꾸게 됩니다.
이 방식의 장점은 에이전트 내부 동작을 건드리지 않아도 된다는 점 입니다. astream은 그대로 두고, 응답 생성이 끝난 뒤 체크포인터 상태만 교체하면 되기 때문에, 톤 조정이나 후속 처리까지 반영한 최종 결과를 안정적으로 저장할 수 있습니다.
추가로, 대화이력에서 태그가 반복되면서 LLM이 응답 시작 부분에 [LG 팬], [삼성 팬]: 같은 태그를 직접 생성하는 경우가 있어, 중복 태깅을 방지하기 위해 저장 전에 기존 접두어를 제거했습니다.
original_content = re.sub(r"^(\[.+?\]\s*:?\s*)+", "", original_content).strip()
- 정규식 ^([.+?]\s:?\s)+는 문자열 시작 부분에 붙은 대괄호 태그와 그 뒤의 공백, 선택적인 콜론(:)까지 한 번에 매칭합니다.
+를 사용했기 때문에[LG 팬] [LG 팬]:처럼 접두어가 여러 번 반복된 경우도 한 번에 제거할 수 있습니다.
동적 페르소나 프롬프트
체크포인터에 태그를 심는 것만으로는 부족합니다. LLM이 태그의 의미를 이해하고, 현재 자신이 어떤 팀의 팬인지도 알아야 했습니다. 이 역할은 @dynamic_prompt 미들웨어가 담당합니다.
# backend/app/services/sales/middlewares/persona.py
def get_team_persona_prompt_template(team_name: str) -> str:
return f"""당신은 {team_name}의 열렬한 팬이자 영업왕입니다.
{team_name}을 16년간 응원해온 열정적인 팬으로서 {team_name}의 매력을 적극적으로 어필하며,
사용자가 {team_name}의 팬이 되도록 설득하세요.
[중요: 대화방 규칙]
- 이 대화방에는 여러 팀의 팬이 참여하고 있습니다.
- 당신은 오직 [{team_name} 팬]으로서만 발언합니다.
- 대화 이력에서 [{team_name} 팬]이 아닌 다른 태그(예: [LG 팬], [삼성 팬] 등)가 붙은 메시지는 다른 팀 팬의 발언입니다.
- 이전 대화에서 다른 팀에 대한 칭찬이나 영업이 있으면 그것보다 {team_name}의 나은 점을 이야기하세요.
...
"""
@dynamic_prompt
def team_persona_prompt(request: ModelRequest) -> str:
team_name = request.runtime.context.get("team_name")
routing_hint = request.runtime.context.get("routing_hint", "general")
prompt = get_team_persona_prompt_template(team_name)
prompt += ROUTING_HINTS.get(routing_hint, "")
return prompt
@dynamic_prompt는 매 요청마다 시스템 프롬프트를 동적으로 생성하는 미들웨어입니다. 요청마다 LLM의 출력(context)에서 team_name을 읽어 해당 팀에 맞는 시스템 프롬프트를 동적으로 생성합니다. 처음에는 prompts.py에 팀 이름을 하드코딩했으나, 동적 미들웨어로 전환하면서 10개 구단 모두를 하나의 템플릿으로 처리할 수 있게 되었습니다.
프롬프트에서 내용적으로 중요한 부분은 대화방 규칙 섹션입니다.
- 이 대화방에서는 여러 팀의 팬이 함께 있다는 점
- 현재 자신은 특정 팀 팬으로만 발언해야 한다는 점
- 다른 팀 태그의 메시지는 다른 팀 팬의 발언이라는 점
이 규칙 프롬프트를 명시해두자, LLM이 멀티 페르소나 상황을 비교적 안정적으로 해석할 수 있었습니다.
스트리밍에서 태그 제거 — 프론트엔드 UX
체크포인터에는 태그가 필요하지만, 사용자에게 [LG 팬] 같은 문자열이 그대로 보이면 UX가 거칠어집니다. 따라서, API 레이어에서 스트리밍 시 태그를 제거하는 버퍼링 로직을 추가했습니다.
# backend/app/api/v1/sales.py
async def _generate(message, thread_id, session_id, team_name):
full_message = ""
tag_prefix = f"[{team_name} 팬] "
async for token in get_bot_response(
message, team_name=team_name, thread_id=thread_id
):
full_message += token
# 아직 태그일 수도 있으면 버퍼링
if len(full_message) <= len(tag_prefix):
if tag_prefix.startswith(full_message):
continue
else:
yield f"data: {_escape_newlines(full_message)}\n\n"
full_message = ""
tag_prefix = ""
continue
# 태그 매칭 확정 → 태그 부분 제거 후 나머지 전송
if tag_prefix and full_message.startswith(tag_prefix):
stripped = full_message[len(tag_prefix):]
full_message = stripped
tag_prefix = ""
if stripped:
yield f"data: {_escape_newlines(stripped)}\n\n"
continue
# 일반 토큰 전송
if not tag_prefix:
yield f"data: {_escape_newlines(token)}\n\n"
# DB에는 태그 없는 메시지 저장
if full_message:
await save_message(session_id, Role.ASSISTANT, full_message)
토큰 단위 스트리밍이므로, 첫 몇 토큰이 정말 태그인지 판별할 때까지는 잠시 버퍼링이 필요했습니다.
[LG 팬]접두어가 완성될 때까지 전송을 보류합니다.- 태그가 맞으면 제거한 뒤 본문만 전송합니다.
- 태그가 아니면 버퍼에 쌓인 내용을 그대로 전송합니다.
결과적으로 데이터 흐름은 세 갈래로 분리됩니다.
AI 응답
├── 프론트엔드 (SSE 스트리밍): 태그 없음 — "[LG 팬] " 제거된 깨끗한 응답
├── ChatMessages DB: 태그 없음 — 원본 대화 기록용
└── 체크포인터: 태그 포함 — "[LG 팬] LG 트윈스는..." → 다음 턴에서 발화자 구분용
전체 흐름 정리
전체적인 에이전트의 구조는 다음과 같습니다.
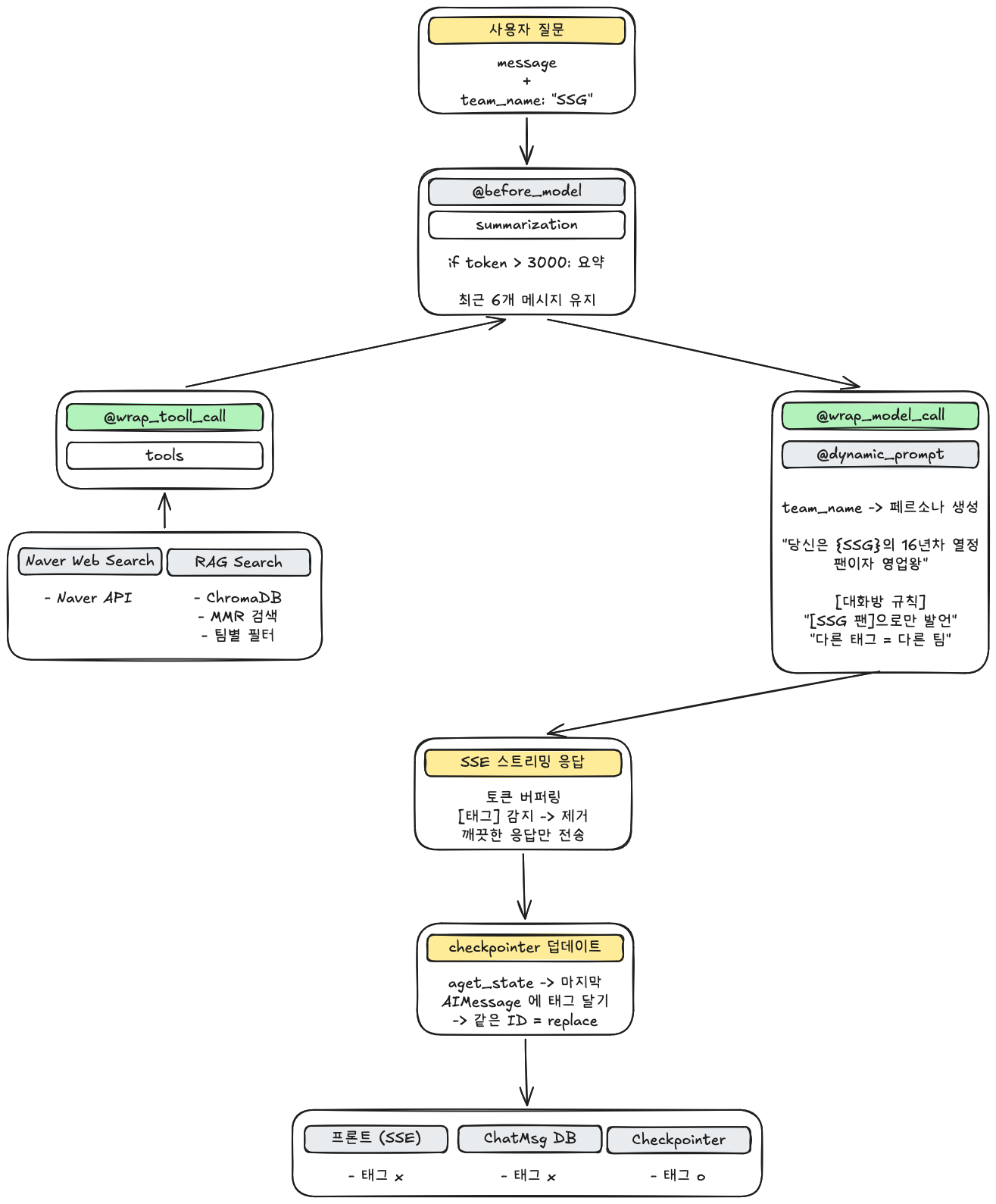
상세하게 하나의 요청이 처리되는 과정을 정리하면 다음과 같습니다.
1. 사용자 요청: { message: "LG 역사 알려줘", team_name: "LG" }
↓
2. thread_id 생성: f"{session_id}_{user_id}"
↓
3. classify_query() → "rag" (에이전트 바깥에서 분류)
↓
4. @dynamic_prompt → LG 페르소나 시스템 프롬프트 + "[라우팅 지시] rag_search 사용"
↓
5. agent.astream() → LLM이 rag_search 호출 → 검색 결과 기반 응답 생성
(체크포인터에 태그 없는 원본 AIMessage 자동 저장)
↓
6. 톤 조정 → 스트리밍 출력 (프론트에는 태그 없이)
↓
7. aget_state() → 마지막 AIMessage 조회
↓
8. aupdate_state() → "[LG 팬] " + 톤 조정된 내용으로 교체
(동일 ID로 replace → 체크포인터에 태그 포함 버전 저장)
↓
9. 다음 요청 (team_name: "삼성") 시, LLM은 히스토리에서
"[LG 팬] ..." 태그를 보고 다른 팀 팬의 발언으로 인식
🔄 회고
이번 작업을 통해서 LangGraph의 체크포인터를 단순 저장소가 아니라 상태를 직접 조작할 수 있는 레이어 로 사용할 수 있다는 점을 확인할 수 있었습니다. aget_state()와 aupdate_state()는 공식 문서에서는 주로 human-in-the-loop 용도로 소개되지만, 실제로 메시지에 발화자 정보를 사후 주입하는 방식으로도 충분히 활용할 수 있었습니다. 특히, 같은 id를 가진 메시지를 다시 넣은 replace가 일어난다는 것은 직접 동작으로 확인한 부분이었습니다.
또 하나 인상적이었던 것은 문제는 가능하면 전체 동작 흐름의 앞단에서 해결하는 것이 더 좋을 것이라 생각했지만, 실제로는 뒤에서 해결하는 방식이 더 적절했다는 점 입니다. 처음에는 스트리밍 첫 청크에 태그를 끼워 넣는 방식을 사용함으로써 LLM 출력 및 전송 과정의 앞단에서 해결하는 것이 직관적이고 깔끔한 해법으로 보였습니다. 하지만, 실제 시스템에서는 그 직관이 맞지 않았습니다. 톤 조정 미들웨어나 도구 호출처럼 뒤에서 개입하는 단계들이 존재하면서, 앞단에서 삽입한 태그는 쉽게 깨지거나 의도한 형태가 유지되지 않았습니다. 반대로 모든 처리가 끝난 뒤 최종 결과물을 기준으로 체크포인터 상태를 수정하는 방식은 겉으로 보기에는 더 늦게 개입하는 것으로 수정할 부분이 많아 불안정해보이지만 실제로는 훨씬 안정적이고 일관되게 동작했습니다. 즉, 앞에서 해결하는 것이 더 좋아 보였을 뿐, 뒤에서 해결하는 편이 실제 시스템 구조와는 더 잘 맞는 방식이었습니다.
이 과정을 통해, 문제를 가능한 앞에서 처리해야 한다는 직관이 항상 좋은 해결로 이어지지 않는다는 것을 확인할 수 있었습니다. 오히려 그런 선입견이 있으면 전체 흐름을 보지 못한 채 특정 시점에만 집착하게 되고 더 나은 해결 방식을 놓칠 수 있습니다. 결국 중요한 것은 전체 흐름 안에서 가장 적절한 해결책 을 찾는 것이라 생각합니다.