[FanMate] RAGAS와 DeepEval로 챗봇 품질 측정하기 — RAG 최적화와 프롬프트 최적화
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
수식이 제대로 표시되지 않는 경우는 랜더링 문제이니, 새로고침하면 해결됩니다.
🧭 배경
이전까지 RAG 파이프라인과 멀티 페르소나 체크포인터 구조를 구현했습니다. 기능 자체는 동작하지만, “이게 잘 되고 있는 건가?”, “프롬프트나 설정을 바꾸면 얼마의 성능 변화가 있는거지?”라는 질문에는 답을 할 수 없었습니다.
또한, RAG 검색이 적절한 문서를 가져오는지, LLM이 검색된 문서에 기반해 충실한 답변을 하는지, 영업왕 페르소나가 의도한 대로 작동하는지 모두 감에 의존해 판단하고 있었습니다. 프롬프트를 조금 바꾸면 조금 나아진 것 같고, chunk_size를 바꾸면 더 좋아진 것 같았지만 그런 판단을 뒷받침할 정량적 근거가 없었습니다.
이 문제를 해결하기 위해 RAGAS와 G-Eval이라는 두 개의 평가 체계를 구축했습니다. 하나는 정보의 정확성과 검색 품질, 다른 하나는 페르소나와 응답 스타일 을 보기 위한 것이었습니다.
평가 체계 개요 — 왜 두개의 축이 필요한가
이번 프로젝트에서는 챗봇 품질을 하나의 기준으로만 보지않고, 정보 품질 과 페르소나 품질 이라는 두 개의 축에서 평가해야한다고 생각했습니다.
RAG 기반 챗봇에서는 검색과 답변의 정확성이 중요합니다. 하지만 FanMate의 영업왕 챗봇은 단순히 정보를 전달하는 것이 아니라, 특정 팀의 팬으로서 사용자를 설득하고 입덕을 유도하는 역할도 수행해야 합니다. 즉, 정확한가 와 영업왕답게 말하는가 는 서로 다른 문제였습니다.
예를 들어, RAG가 문서 검색을 잘해서 응답이 “삼성 라이온즈는 1982년에 창단되었습니다.” 와 같이 정확하지만 백과사전식으로만 대답한다면, 정보는 맞지만 영업왕 챗봇으로서는 좋은 답변이라고 보기 어렵습니다. 반대로 톤은 자연스럽고 팬심도 살아 있지만, 검색 문서에 없는 내용을 자신 있게 말하고 있다면 그것 역시 좋은 응답이 아닙니다.
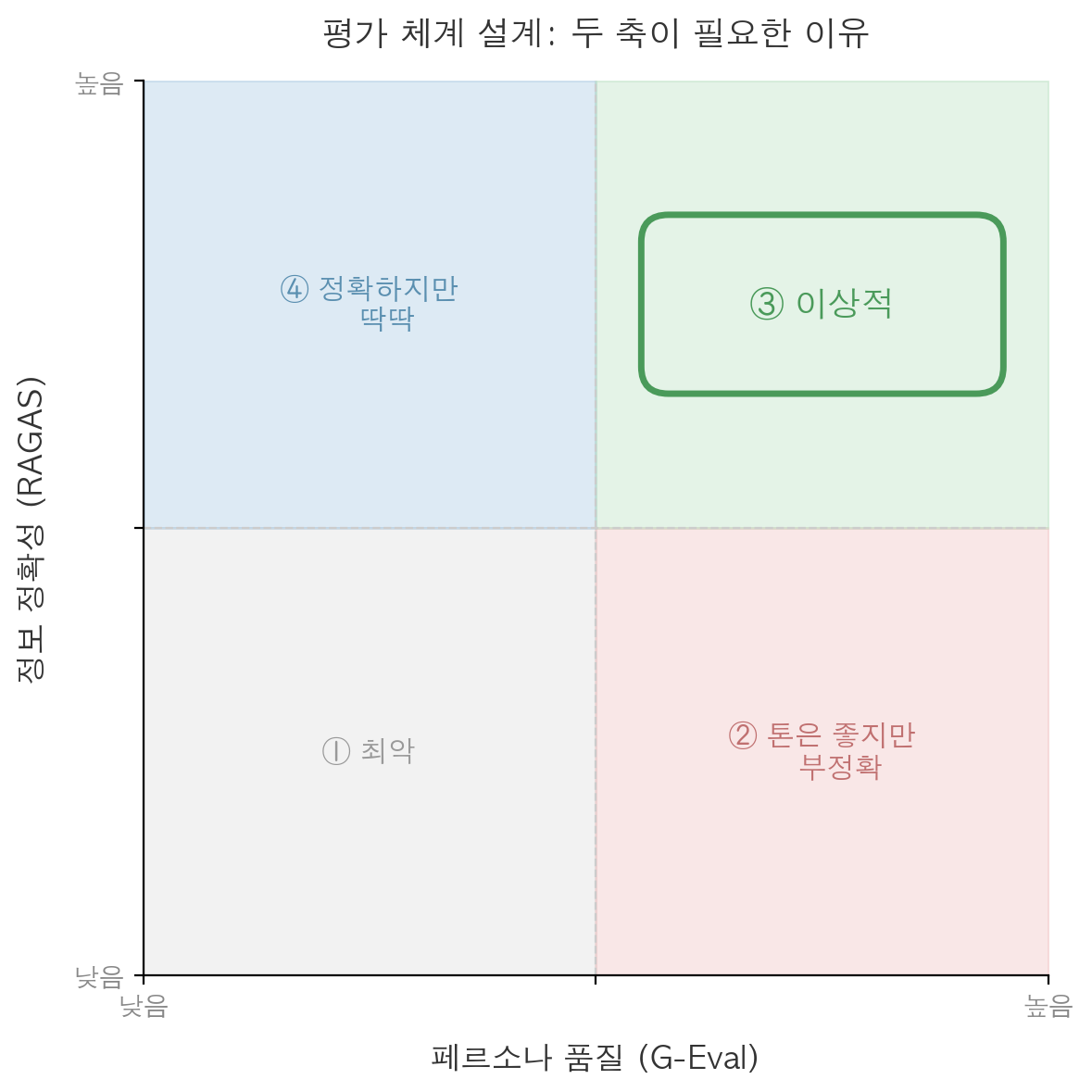
서비스를 구축하면서 가져야하는 목표는 ③번 정확하면서 페르소나가 살아있는 응답 입니다. 이를 위해 평가 모듈도 두 갈래로 분리해 구성했습니다.
평가 체계 구축
1. RAGAS — 검색과 답변의 정확성 평가
무엇을 평가했는가
RAGAS는 RAG 파이프라인의 검색 품질과 답변 정확성을 평가하기 위한 프레임워크 입니다. RAGAS를 이용해 사용한 평가 매트릭은 다음과 같습니다.
| 메트릭 | 평가 대상 | 의미 | 계산 방식 요약 |
|---|---|---|---|
| Faithfulness | 생성된 답변 | 답변이 검색 문서에 근거하는가 | 응답의 claim 중 문맥으로 뒷받침되는 claim의 비율 |
| Response Relevancy | 생성된 답변 | 답변이 질문과 관련 있는가 | 응답이 질문 의도에 얼마나 부합하는지 평가 |
| Context Precision | 검색된 문서 | 검색된 문서가 질문에 적절한가 | 상위 rank에 relevant chunk가 얼마나 잘 배치됐는지 평가 |
- Faithfulness Faithfulness는 답변이 검색된 문서에 얼마나 충실한가를 측정 합니다. 응답 안의 주장(claim)을 나눈 뒤, 각 claim이 retrieved context로 부터 추론 가능한지 확인하고 비율로 점수를 계산합니다. 즉, 할루시네이션을 탐지 하는 데 가까운 지표입니다.
Response Relevancy Response Relevancy는 답변이 질문에 얼마나 관련 있는가를 평가 합니다. 질문 의도와 잘 맞는 답변이면 점수가 올라가고, 질문과 직접 관련 없는 부가 설명이 많거나 답이 빗나가면 점수가 내려갑니다. 이 지표는 질문과 응답의 관련성을 보는 것이지, 사실 정확성 자체를 직접 평가하는 것은 아닙니다.
Context Precision Context Precision은 retriever가 관련 있는 chunk를 상위에 잘 배치했는가를 평가 합니다. relevant한 문서가 검색되었더라도 뒤쪽에 몰려 있으면 점수가 낮아질 수 있습니다. 즉, “관련 문서가 포함되었는가”보다 검색 순위가 얼마나 잘 정렬되었는가 를 보는 데 가깝습니다. \[\text{Context Precision@K}=\frac{\sum_{k=1}^{K}(\text{Precision@k}\cdot v_k)}{\text{Total number of relevant items in top K}}\] \[\text{Precision@k}=\frac{\text{true positives@k}}{\text{true positives@k}+\text{false positives@k}}\]
여기서 $v_k$ 는 rank $k$ 의 chunk가 relevant하면 1, 아니면 0인 indicator입니다.
어떻게 평가했는가?
평가 파이프라인
평가용 LLM과 서비스 LLM은 분리했습니다. 서비스 LLM (ClovaX)으로 실제 응답을 생성하고, 평가용 LLM(gpt-4o-mini)로 품질을 판정했습니다. 같은 모델이 생성과 평가를 동시에 해도 괜찮지만, 같은 모델을 사용시 혹시 모를 자기 편향이 있을 수 있고 평가는 상대적으로 성능이 더 좋은 모델로 하는 것이 맞다고 판단해 분리하였습니다.
# evaluation/ragas/evaluator.py
class RAGEvaluator:
def __init__(self, config):
# 평가용 LLM: gpt-4o-mini (판정 일관성을 위해 OpenAI)
self.evaluator_llm = LangchainLLMWrapper(
ChatOpenAI(model=config.evaluator_model, temperature=0)
)
# 서비스 LLM: ClovaX (실제 서비스와 동일)
self.service_llm = ChatClovaX(
model=settings.LLM_MODEL,
temperature=0.3,
)
self.metrics = [
Faithfulness(llm=self.evaluator_llm),
ResponseRelevancy(llm=self.evaluator_llm, embeddings=self.evaluator_embeddings),
LLMContextPrecisionWithoutReference(llm=self.evaluator_llm),
]
LLMContextPrecisionWithoutReference를 선택한 이유는 정답 레퍼런스(ground truth) 없이도 검색 품질을 평가할 수 있기 때문입니다.- 10개 구단 x 5개 질문 = 50개에 대해 정답을 일일이 작성하는 비용을 줄일 수 있었습니다.
테스트 데이터셋
# evaluation/ragas/datasets.py
TEST_QUESTIONS = {
"LG": [
"LG 트윈스 마스코트는 뭐야?",
"LG 트윈스 홈구장은 어디야?",
"LG 트윈스 우승 연도 알려줘",
"LG 트윈스 역대 감독은 누가 있어?",
"LG 트윈스 창단년도는?",
],
# ... 10개 구단 × 5개 질문
}
테스트 질문은 의도적으로 기본 정보 질문으로 구성했습니다. 마스코트, 홈구장, 우승 기록, 창단년도처럼 문서에 반드시 포함되어 있어야 하는 내용으로 구성하면, 검색 파이프라인이 정상적으로 동작하는지 확인하기 좋았기 때문입니다.
응답 생성을 위한 프롬프트
응답 생성에서는 중립적인 전달 프롬프트를 사용했습니다. 영업왕 페르소나 프롬프트를 그대로 사용하면 감탄사나 스타일 요소가 Faithfulness 점수에 노이즈를 줄 수 있다고 생각해, 순수하게 RAG 품질만 측정하려고 했습니다.
# evaluation/ragas/evaluator.py
def _generate_response(self, query: str, contexts: list[str]) -> str:
context_text = "\n\n".join(contexts)
messages = [
SystemMessage(
content=f"""KBO 야구 전문가로서 참고 자료 기반으로 답변하세요.
참고 자료에 없는 내용은 답변하지 마세요.
참고 자료:
{context_text}
"""
),
HumanMessage(content=query),
]
return self.service_llm.invoke(messages).content
평가 실행
각 질문에 대해 RAG 검색 -> 응답 생성 -> RAGAS 평가 순서로 진행됩니다.
def _create_sample(self, query, team):
# 1. RAG 검색 (실제 retriever 사용)
docs = rag_search(query, team=team, k=self.config.retrieval_k)
contexts = [doc.page_content for doc in docs]
# 2. 중립적 프롬프트로 응답 생성 (페르소나 없음)
response = self._generate_response(query, contexts)
# 3. RAGAS 샘플 구성
return SingleTurnSample(
user_input=query,
response=response,
retrieved_contexts=contexts,
)
2. G-Eval — 페르소나 품질 평가
무엇을 평가했는가
G-Eval은 LLM을 평가자로 활용해 응답의 정성적 품질을 평가하는 LLM-as-a-judge 방식 입니다. RAGAS가 “검색과 답변의 정확성”을 본다면, G-Eval은 “응답이 서비스 의도에 맞는 톤과 역할을 수행하고 있는지”를 평가하는 데 적합합니다.
영업왕 챗봇의 특성에 맞춰 6개의 커스텀 매트릭을 설계했습니다.
- 열정적인 팬처럼 말하고 있는가?
- 사용자를 친근하게 맞이하고 환영하는가?
- 팀의 매력을 설득력 있게 어필하고 있는가?
- 입덕 포인트를 구체적으로 제시하고 있는가?
- 제공하는 정보가 정확하고 근거에 맞는가?
- 사용자가 대화를 계속 이어가고 싶게 만드는가?
여기서 제공하는 정보에 대한 정확성도 같이 매트릭으로 만든 이유는 “톤은 좋아졌지만 정확성은 떨어졌다”와 같은 trade-off를 감지하기 위해 추가해두었습니다.
어떻게 평가했는가
평가 기준 구현
# evaluation/deepeval/metrics.py
# 1. 열정적인 팬 페르소나
fan_persona = GEval(
name="열정_팬_페르소나",
criteria="16년차 열정 팬처럼 팀에 대한 애정과 자부심이 느껴지는가",
evaluation_steps=[
"팀에 대한 애정이 자연스럽게 드러나는지 확인",
"오랜 팬만 아는 디테일이나 애칭을 적절히 사용하는지 확인",
"팀의 장점을 자랑스럽게 소개하는지 확인",
"너무 딱딱하거나 객관적인 톤이면 감점",
"진정성 없이 과장만 하면 감점",
],
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
# 2. 친근함과 환영 분위기
friendliness = GEval(
name="친근함_환영",
criteria="야구 뉴비를 따뜻하게 환영하고 친근하게 대하는가",
evaluation_steps=[
"새로운 팬을 환영하는 따뜻한 분위기인지 확인",
"어려운 용어 없이 쉽게 설명하는지 확인",
"질문을 바보 같다고 느끼게 하지 않는지 확인",
"함께 응원하자는 동료 의식이 느껴지는지 확인",
"차갑거나 거리감 있는 톤이면 감점",
],
)
# 3. 영업력 (팀 매력 어필)
# 4. 입덕 포인트 제시
# 5. 정보 정확성 (할루시네이션 방지)
# 6. 대화 유도
각 메트릭의 evaluation_steps에 구체적인 평가 기준을 단계별로 제시하여 LLM 판정의 일관성을 높였습니다. “진정성 없이 과장만 하면 감점”처럼 감점 기준도 명시했습니다.
평가 파이프라인
# evaluation/deepeval/evaluator.py
class GEvalEvaluator:
def _generate_response(self, query, contexts, team):
# 실제 서비스 프롬프트를 그대로 사용
system_prompt = get_team_persona_prompt_template(team)
system_prompt += f"\n\n[검색된 참고 자료]\n{context_text}"
# ...
def _create_test_case(self, query, team):
docs = rag_search(query, team=team, k=self.config.retrieval_k)
contexts = [doc.page_content for doc in docs]
response = self._generate_response(query, contexts, team)
return LLMTestCase(
input=query,
actual_output=response,
retrieval_context=contexts,
)
테스트 데이터셋 — RAGAS와의 차이
# evaluation/deepeval/datasets.py
SALES_TEST_QUESTIONS = {
"LG": [
"LG 트윈스 입덕하려는데 뭐부터 알아야 해?",
"LG 트윈스 응원하면 뭐가 좋아?",
"LG 팬들 분위기 어때?",
"LG 트윈스 직관 가려면 어디로 가?",
"LG 트윈스에서 꼭 알아야 할 선수 누구야?",
],
# ...
}
RAGAS의 기본 정보 질문과 달리, G-Eval의 질문은 영업 시나리오를 반영합니다. “입덕하려는데”, “뭐가 좋아?”, “분위기 어때?” 같은 질문은 야구 뉴비가 실제로 물어볼 법한 내용이며, 이에 대해 영업왕이 얼마나 매력적으로 팀을 어필하는지를 평가합니다.
RAG 최적화 실험
평가 체계가 갖춰진 뒤에는 chunk size, 검색 방식, retriever type 등 여러 변수에 대한 실험 자동화를 구현했습니다. 다양한 조건의 벡터DB를 빌드하고, retriever_type * search_type * k 조합을 순회하며 RAGAS 평가를 자동 실행하도록 구성했습니다. 또한, use_rag 플래그를 추가하여 RAG 없이 LLM만으로 답변하는 baseline 성능도 측정할 수 있게 했습니다. RAG 파이프라인이 실제로 답변 품질을 향상시키는지 확인하기 위한 대조군입니다.
# evaluation/run_experiment.py
PERSIST_DIRECTORIES = [
"vectordb/chroma_300_50",
"vectordb/chroma_600_150",
"vectordb/chroma_800_150",
"vectordb/chroma_1200_200",
"vectordb/mini_chroma_300_50",
"vectordb/mini_chroma_600_150",
"vectordb/mini_chroma_800_150",
"vectordb/mini_chroma_1200_200",
]
RETRIEVER_TYPES = ["dense", "hybrid"]
SEARCH_TYPES = ["mmr", "similarity"]
K_VALUES = [3, 5]
def build_configs(persist_dirs=None, retrievers=None, searches=None, ks=None):
"""실험 조건의 모든 조합(cartesian product)으로 EvalConfig 리스트를 생성"""
persist_dirs = persist_dirs or PERSIST_DIRECTORIES
retrievers = retrievers or RETRIEVER_TYPES
searches = searches or SEARCH_TYPES
ks = ks or K_VALUES
configs = []
for db, retriever, search, k in product(persist_dirs, retrievers, searches, ks):
configs.append(
EvalConfig(
persist_directory=db,
retriever_type=retriever,
search_type=search,
retrieval_k=k,
)
)
return configs
def run_experiments(configs, teams=None):
"""모든 실험 조건을 순차 실행하고 결과를 반환"""
all_results = []
for idx, config in enumerate(configs, 1):
print(f"\n 실험 [{idx}/{len(configs)}] {config.experiment_name}")
evaluator = RAGEvaluator(config)
result = evaluator.evaluate_all(teams=teams, save=True)
all_results.append(result)
return all_results
평가 결과는 타임스탬프 기반 JSON 파일로 저장됩니다.
{
"timestamp": "2026-02-09T...",
"config": {
"persist_directory": "vectordb/chroma_800_150",
"retriever_type": "hybrid",
"search_type": "similarity",
"retrieval_k": 5
},
"average": {
"faithfulness": 0.747,
"answer_relevancy": 0.408,
"context_precision": 0.664
},
"teams": {
"LG": { "num_samples": 5, "scores": { ... } },
"두산": { "num_samples": 5, "scores": { ... } }
}
}
실험 결과
구체적으로 다음 조합을 자동으로 비교하였습니다.
- retriever_type: dense(벡터 검색만) vs hybrid(BM25 + 벡터 앙상블)
- search_type: mmr vs similarity
- k값: 반환 문서 개수 (k: 3, 5)
- chunk_size / chunk_overlap: 청킹 파라미터 (chunk_size 300/600/800/1200)
테스트 질문도 5개부터 시작해 최종적으로 25개(5개 카테고리 x 5개)까지 확장하였습니다.
1차 실험 — 다양한 RAG 설정 조합 비교
총 64개 조합(chunk_size 4종 × 데이터셋 2종 × retriever 2종 × search 2종 × k 2종)을 실행했습니다.
search_type별 3개 메트릭 비교 (증강 데이터셋)
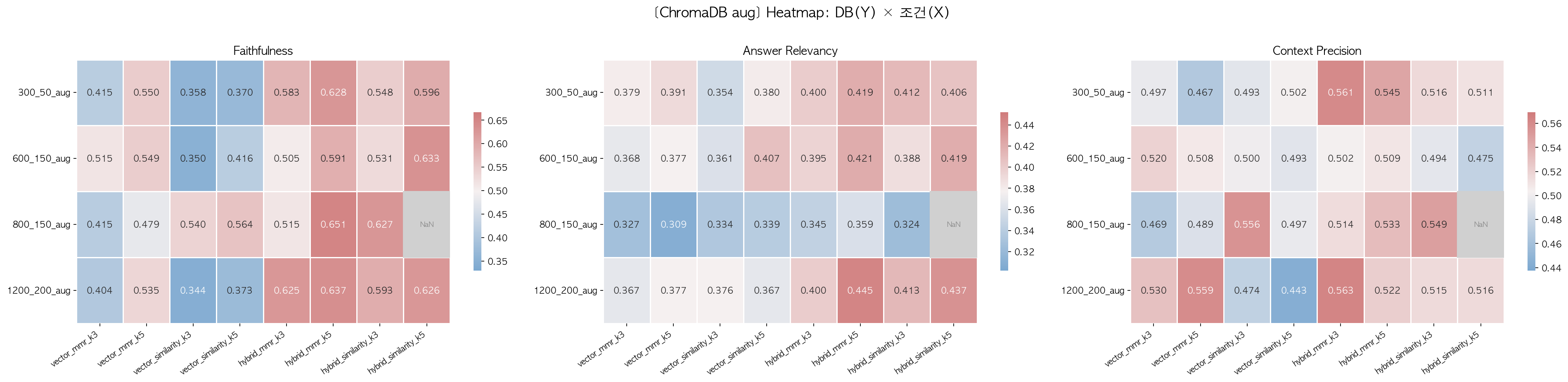
| search_type | chunk_size | retriever | k | Faithfulness | Answer Relevancy | Context Precision |
|---|---|---|---|---|---|---|
| MMR | 800_150 | hybrid | 5 | 0.651 | 0.399 | 0.533 |
| MMR | 800_150 | hybrid | 3 | 0.515 | 0.395 | 0.505 |
| MMR | 800_150 | vector | 5 | 0.479 | 0.375 | 0.497 |
| Similarity | 800_150 | hybrid | 5 | 0.627 | 0.403 | 0.515 |
| Similarity | 800_150 | hybrid | 3 | 0.564 | 0.408 | 0.520 |
| Similarity | 800_150 | vector | 5 | 0.540 | 0.378 | 0.497 |
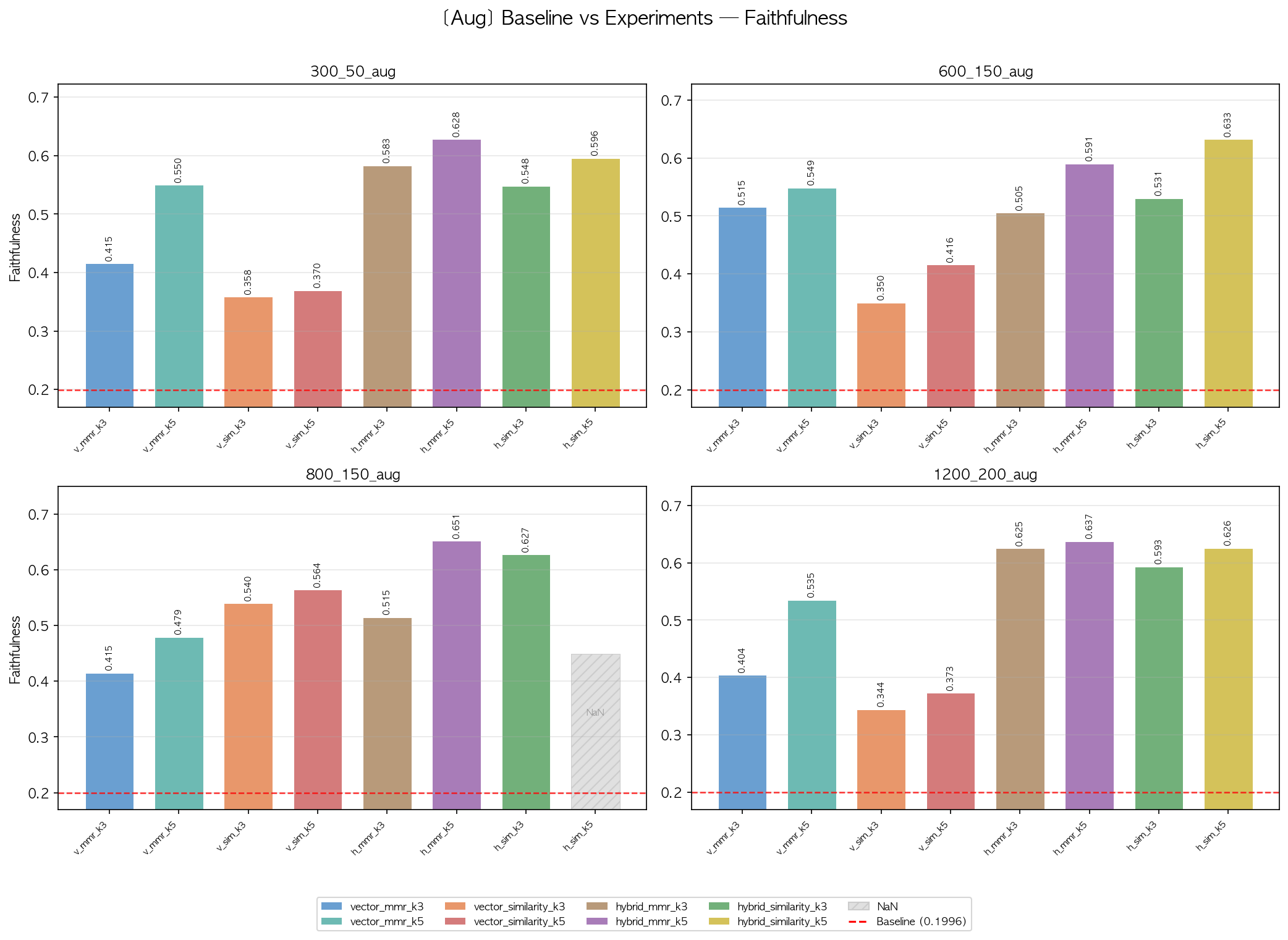
Faithfulness 상위 조합 (증강 데이터셋)
| chunk_size | 조합 | Faithfulness |
|---|---|---|
| 800_150 | hybrid_mmr_k5 | 0.651 |
| 800_150 | hybrid_similarity_k5 | 0.627 |
| 1200_200 | hybrid_mmr_k5 | 0.637 |
| 1200_200 | hybrid_similarity_k5 | 0.626 |
| 600_150 | hybrid_similarity_k5 | 0.633 |
| 300_50 | hybrid_mmr_k5 | 0.628 |
1차 실험의 핵심 관찰:
800_150_aug + hybrid_mmr_k5조합이 Faithfulness 전체 1위(0.651)였지만, 절대적으로 높은 점수는 아니었습니다.- Context Precision도 0.533 수준으로, 검색된 청크의 품질에 개선 여지가 있었습니다.
- 검색된 청크를 직접 확인한 결과,
MarkdownHeaderTextSplitter와RecursiveCharacterTextSplitter사용으로 “자세한 내용은 LG 트윈스/팀 컬러 문서를 참고하십시오.”와 같은 stub chunk가 다수 포함되어 있었습니다. - 전반적으로 Hybrid가 Dense보다, k=5가 k=3보다 우수한 경향이 일관되게 나타났습니다.
2차 실험 — Stub chunk 제거 후 재실험
stub chunk를 제거한 데이터셋(stub)으로 재실험했습니다.
Stub 제거 후 전체 조합 결과

stub 제거 후 전체 조합의 히트맵을 보면, 800_150_stub 데이터셋에서 전반적으로 높은 점수가 나왔습니다.
hybrid_similarity_k3가 Faithfulness 단독 1위였지만, k5 조합이 세 지표 모두 균형 있게 높아서 최종 선택했습니다.
800/150 + hybrid_mmr_k5에서 Stub 제거 전후 비교:
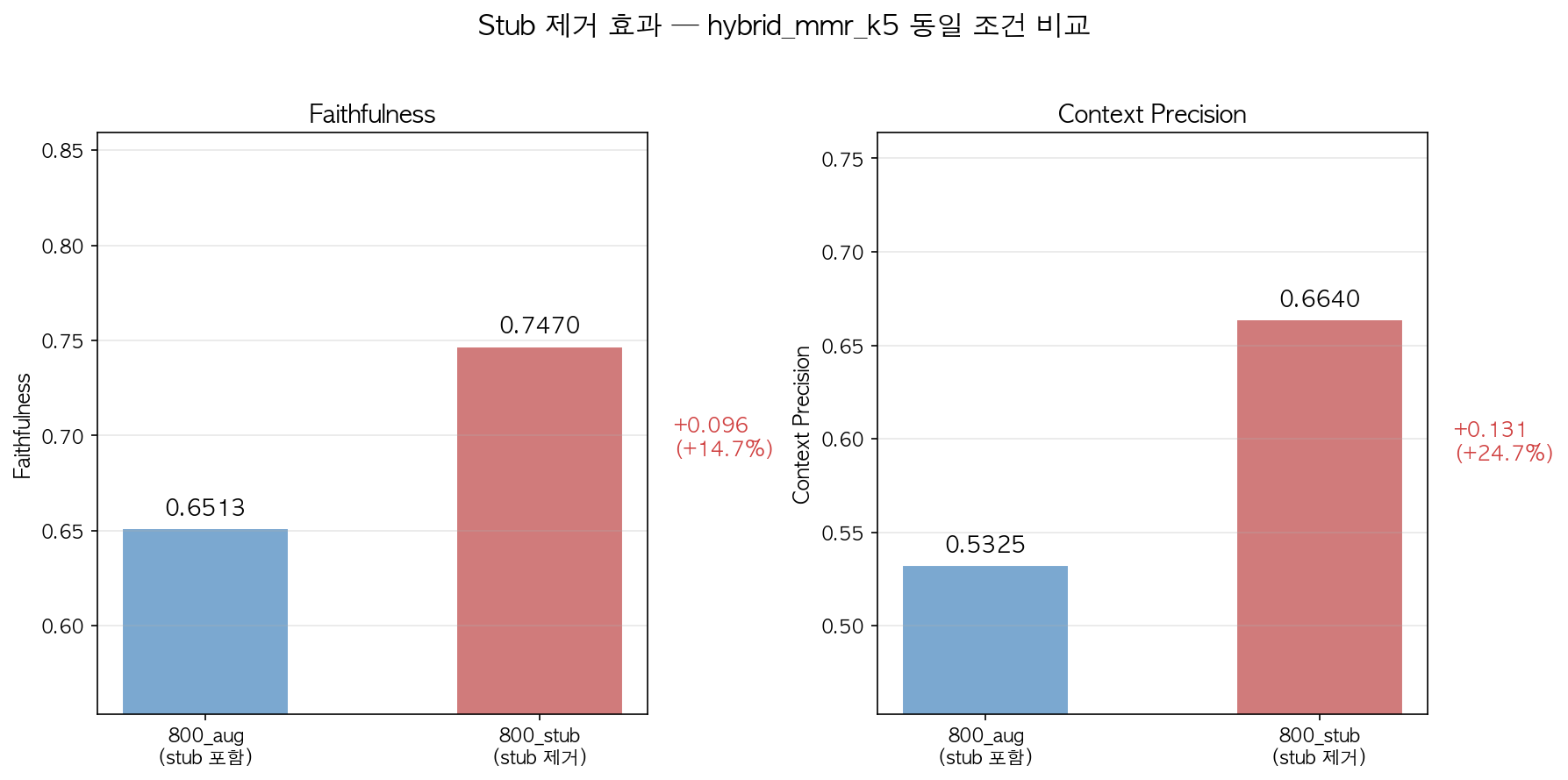
| 지표 | stub 포함 (aug) | stub 제거 (stub) | 개선율 |
|---|---|---|---|
| Faithfulness | 0.651 | 0.747 | +14.7% |
| Answer Relevancy | 0.359 | 0.408 | +13.6% |
| Context Precision | 0.533 | 0.664 | +24.6% |
Context Precision이 24.6% 향상된 것은 stub 청크가 “관련 없는 검색 결과”의 주범이었음을 보여줍니다.
실험 요약 및 인사이트
Baseline(RAG 없이 LLM만 사용) → 1차 실험(RAG 적용) → 2차 실험(stub 제거)의 Faithfulness 변화를 정리하면 다음과 같습니다.
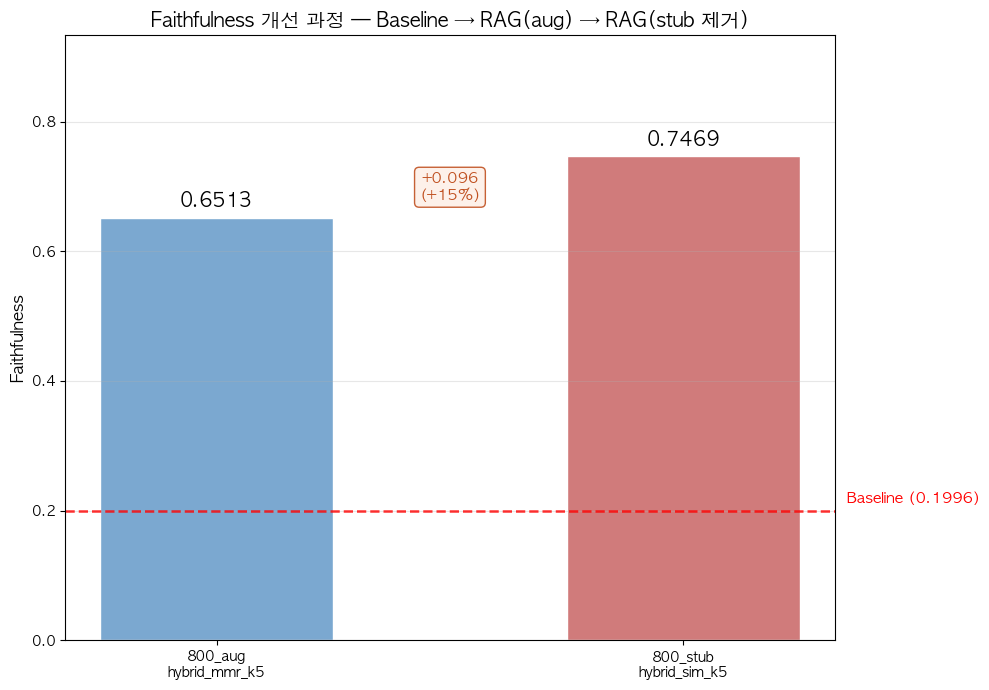
| 단계 | Faithfulness | 개선 |
|---|---|---|
| Baseline (RAG 없음) | 0.200 | — |
| 1차: 800_aug + hybrid_mmr_k5 | 0.651 | +226% (Baseline 대비) |
| 2차: 800_stub + hybrid_sim_k5 | 0.747 | +15% (1차 대비) |
RAG 파이프라인 도입만으로 Baseline 대비 3배 이상 개선되었고, stub chunk 제거라는 데이터 전처리 개선이 추가로 +15%를 끌어올렸습니다.
- 데이터 전처리가 검색 파라미터 튜닝보다 훨씬 큰 영향을 줍니다. stub chunk 제거 하나로 Context Precision이 +27% 올랐는데, retriever나 search_type 변경으로는 이 정도 개선이 불가능했습니다.
- Hybrid(BM25 + Vector)가 Dense 단독보다 효과적이었습니다. BM25가 키워드 매칭으로 벡터 검색이 놓치는 정확한 고유명사(선수 이름, 연도 등)를 보완해주었습니다.
- 초기에 선택했던 MMR보다 Similarity가 약간 더 나은 결과를 보였습니다. 메타데이터 필터링(
$or)이 이미 검색 범위를 좁혀주고 있어서, MMR의 다양성 확보 효과가 크지 않았던 것으로 분석합니다. - k=5가 k=3보다 전반적으로 우수했습니다. 충분한 컨텍스트를 제공하는 것이 답변 품질에 긍정적이었습니다.
- 800자 chunk_size + 150자 overlap이 최적이었습니다. 300자는 문맥이 부족했고, 1200자는 노이즈가 많았습니다.
프롬프트 최적화
서비스 컨셉 정립과 사용자 시나리오·엣지 케이스 구조화
기본적인 프롬프트를 작성한 뒤 챗봇이 의도한 방식으로 동작하도록 만들기 위해 먼저 엣지 케이스를 도식화했습니다.
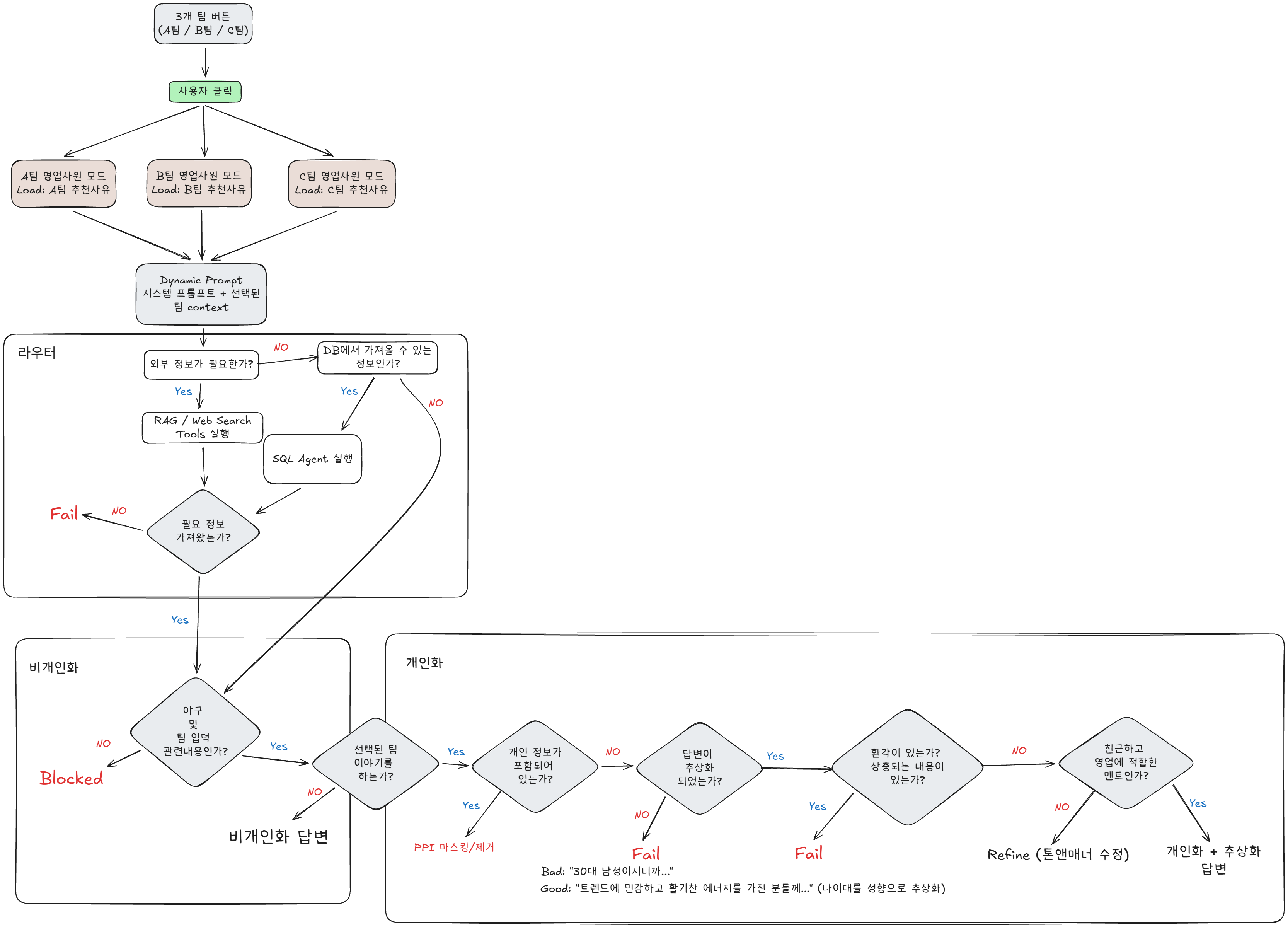
- 영업왕이 실제 대화에서 마주할 수 있는 상황을 분기별로 정리하고, 각 분기마다 기대하는 응답 품질 기준을 정의하였습니다.
- 비개인화 경로: 야구/입덕과 무관한 질문은 차단, 팀 이야기가 아닌 일반 야구 질문은 페르소나 없이 응답
- 개인화 경로: 개인정보 포함 여부, 답변의 추상화 수준, 환각/날조 여부, 톤앤매너 적합성까지 단계별로 정의 및 검증
- 이를 기반으로 실제 답변을 수집하고, 귀납적으로 엣지 케이스를 검출하며 프롬프트와 파이프라인을 반복 개선하였습니다.
G-Eval 기반 프롬프트 반복 개선
G-Eval 평가 체계를 구축한 뒤, 프롬프트를 수정할 때마다 평가를 실행하여 수치 변화를 추적했습니다. 엣지 케이스 분석과 프롬프트 수정을 반복하면서, 미묘한 차이를 수치로 확인하며 개선 방향을 잡아갈 수 있었습니다.
아래는 프롬프트 v1(엣지 케이스 반영 전)과 v2(시나리오 기반 프롬프트 개선 후)의 비교 결과입니다.
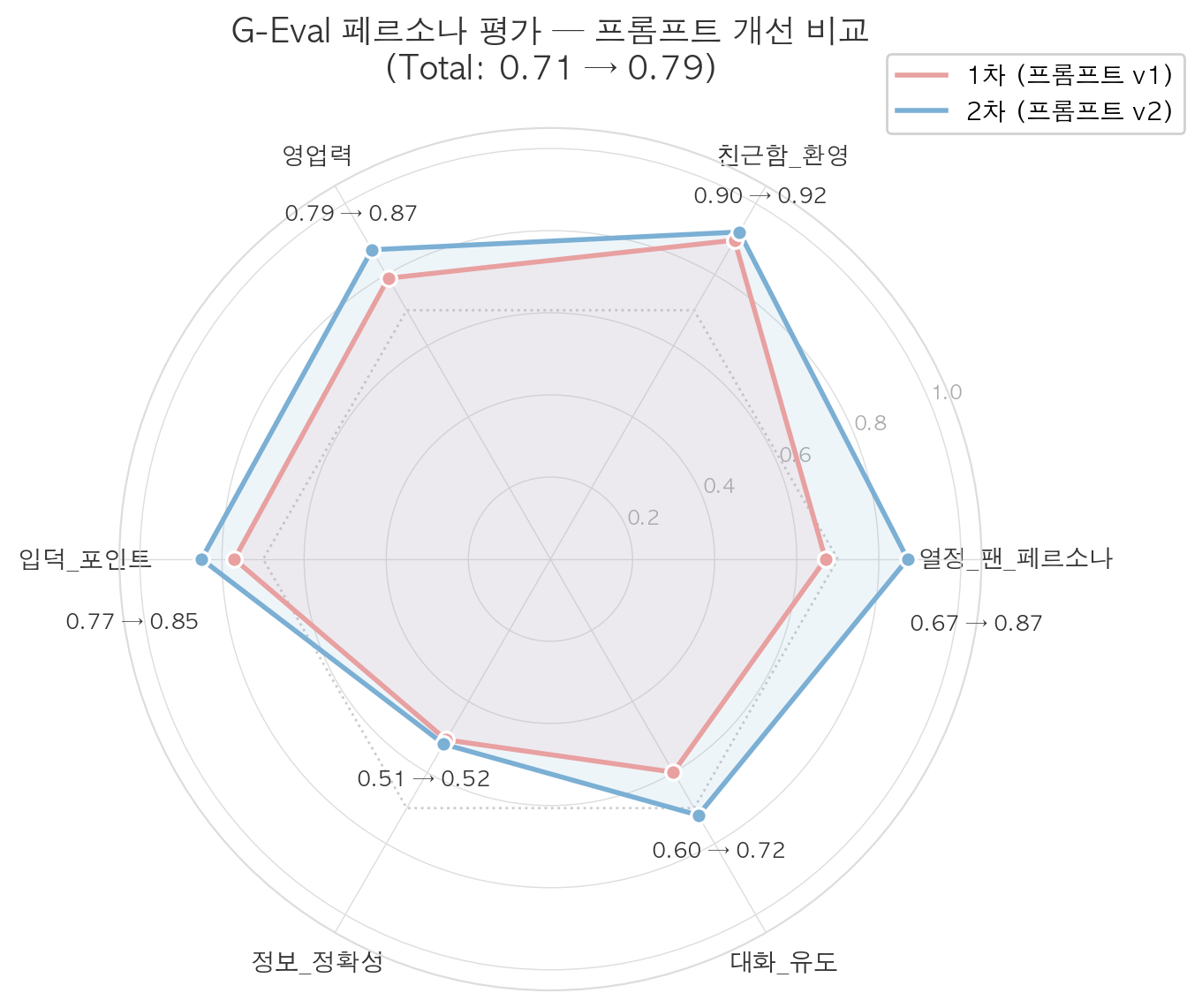
프롬프트 v1 → v2 개선 결과
| 메트릭 | v1 | v2 | 변화 |
|---|---|---|---|
| 열정팬페르소나 | 0.67 | 0.87 | +0.20 |
| 친근함_환영 | 0.90 | 0.92 | +0.02 |
| 영업력 | 0.79 | 0.87 | +0.08 |
| 입덕_포인트 | 0.77 | 0.85 | +0.08 |
| 정보_정확성 | 0.51 | 0.52 | +0.01 |
| 대화_유도 | 0.60 | 0.72 | +0.12 |
| Total | 0.71 | 0.79 | +0.08 |
개선 분석:
- 열정팬페르소나(+0.20) 가 가장 큰 폭으로 개선되었습니다. 엣지 케이스 분석에서 “팬심이 부족한 응답”을 식별한 뒤, 프롬프트에 팀별 애칭·디테일 사용 지시를 강화한 결과입니다.
- 대화 유도(+0.12) 도 눈에 띄게 올랐습니다. 후속 질문을 자연스럽게 유도하는 패턴을 프롬프트에 추가한 효과입니다.
- 정보 정확성(0.51 → 0.52) 은 거의 변화가 없었습니다. 이 지표는 프롬프트 톤 조정이 아닌 RAG 검색 품질에 의존하는 영역이기 때문에, 프롬프트 수정만으로는 개선이 어려웠습니다. 실제로 RAGAS 실험에서 stub 제거와 retriever 변경이 이 영역의 개선에 더 효과적이었습니다.
- 친근함 환영(0.90 → 0.92) 은 v1에서부터 이미 높았습니다. 서비스 특성상 “환영하는 톤”은 기본 프롬프트에서도 자연스럽게 나오는 부분이었습니다.
이 결과를 통해, 프롬프트 수정은 페르소나 품질을 개선하는 데에는 효과적이지만, 정보 정확성은 RAG 파이프라인 단에서 함께 다뤄야 한다는 점을 수치적으로 확인할 수 있었습니다. 아쉬운 점은 완전히 초기 상태의 프롬프트를 정량적 지표를 쌓아나가지 못했다는 점입니다. 어느 정도 프롬프트를 다듬고 방향을 잡아가던 중간 단계에서 평가 체계를 완성했기에 “처음부터 끝까지의 개선 과정”을 그려내지 못했습니다. 그럼에도 감에 의존하던 프롬프트 수정을 수치 기반의 반복 개선으로 전환했다는 점에서 의미가 있고 비슷한 경우 평가 체계를 조기에 구축하는 것의 중요성을 알 수 있었습니다.
회고
이번 작업을 하며 가장 크게 느낀 점은, “잘 되는 것 같다” 라는 감각만으로는 시스템을 개선해서는 안되며, 정량적 평가와 정성적 평가가 함께 이루어져야 한다는 것이었습니다. 이전 프로젝트에서도 RAG를 구현하기는 했지만, 성능 자체를 본격적으로 점검하거나 분석하지는 못했습니다. 또한 프롬프트를 수정한 뒤 응답이 조금 나아진 것 같다고 느껴지더라도, 그것이 실제 개선인지 아니면 제 기대가 반영된 해석인지 판단하기 어려웠습니다. 그래서 이번 작업은 단순히 “기능을 구현했으니 끝” 혹은 “~을 바꿨는데 성능이 오른 것 같다”의 수준에서 끝나는 것이 아니라, 시스템을 객관적인 기준과 수치로 해석하고 지속적으로 업데이트할 수 있는 구조를 만들어나가는 과정이었다고 생각합니다.
특히, Fanmate에서 단순히 정보 정확성만 살펴보는 것이 아니라 페르소나 수행이 중요한 요소라 생각했고, 이를 위해 RAGAS와 G-Eval이라는 두 축 평가체계를 나눠 설계한 경험은 매우 의미있었다고 생각합니다. 서비스나 기능에 대해 보다 입체적으로 바라볼 수 있는 경험이었던 것 같습니다.
또한, 이러한 평가체계를 구축하면서 문제의 원인을 더 구체적으로 파악할 수 있었습니다. 단순히 성능이 낮다거나 좋아졌다는 사실을 확인하는 데 그치지 않고, stub chunk 같은 데이터 전처리 이슈가 검색 품질을 크게 떨어뜨리고 있었다는 점, 프롬프트 수정은 페르소나 개선에는 효과적이지만 정보 정확성 자체를 크게 끌어올리지 못한다는 점을 구분해서 확인할 수 있었습니다.
서비스 측면에서는 최적화된 RAG의 설정을 찾아 Faithfulness를 크게 향상시키며 할루시네이션을 줄이고, 모델이 더 정확한 문서를 참조할 수 있도록 개선할 수 있었습니다. 프롬프트 측면에서는 엣지 케이스를 구조화하고 반복적으로 수정하면서 팬 페르소나의 품질을 역시 한층 끌어올릴 수 있었습니다.
이번 경험을 통해 좋은 챗봇은 모델 하나로 만들어지는 것이 아니라, 데이터, 검색, 프롬프트, 평가 체계가 함께 맞물릴 때 비로소 완성도를 가져갈 수 있다는 것을 확인할 수 있었습니다. 앞으로는 기능 구현 뿐 아니라 평가 기준과 체계를 함께 설계해 빠르고 명확하게 개선할 수 있는 개발 사이클을 만들어나가야겠다고 느꼈습니다.