Class-Balanced Loss Based on Effective Number of Samples 논문 읽기
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
수식이 제대로 표시되지 않는 경우는 랜더링 문제이니, 새로고침하면 해결됩니다.
Motivation
최근 진행 중인 프로젝트에서 클래스 불균형(Class Imbalance) 문제가 뚜렷하게 나타났습니다.
이 문제를 해결하기 위한 이론적 기반을 찾던 중, Yin Cui et al.(CVPR 2019)의 “Class-Balanced Loss Based on Effective Number of Samples” 논문을 읽게 되었습니다.
이 논문은 단순한 클래스 빈도 조정이 아닌, ‘유효 샘플 수(Effective Number of Samples)’라는 개념을 통해
데이터 중복과 정보량의 한계를 수학적으로 설명한 흥미로운 접근을 제시합니다.
Introduction
데이터 불균형
- Visual recognition 에서 Deep Convolutional Neural Networks (CNNs)의 성공은 실제 대규모의 라벨링 데이터셋 등장하면서 이루어졌습니다.
- 하지만, 이런 학습용 데이터셋과 실제(real-world) 데이터셋에는 차이가 있습니다.
| 구분 | 특징 |
|---|---|
| 실험 데이터셋 (CIFAR, ImageNet 등) | 클래스 분포가 균일 |
| 실제(real-world) 데이터셋 | 일부 클래스가 대부분의 샘플 차지 |
- 이렇게 일부 클래스가 샘플의 대부분의 차지하면 데이터는 아래와 같은 long-tail의 분포를 가지고, long-tail 분포는 아래와 같은 특징을 가지고 있습니다.
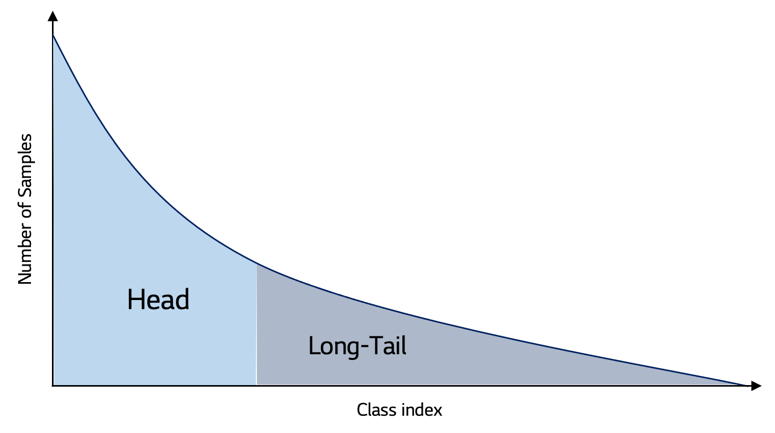
- 소수의 지배적인(head) 클래스가 샘플의 대부분을 구성하고, 다수의 긴 꼬리 클래스들은 소수을 샘플로만 존재합니다.
- 모델 학습과 관련해서,불균형 데이터로 학습된 CNN은 소수 클래스에서 성능이 현저히 낮다는 문제점을 가지고 있습니다.
데이터 불균형과 관련해서 이전의 연구들
1. Re-sampling
- Re-Sampling에는 크게 Under-sampling 과 Over-sampling이 있습니다.
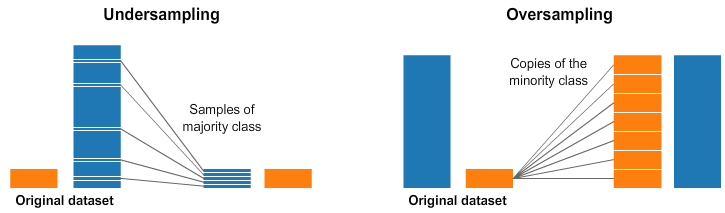
- Under-sampling
- 샘플 데이터가 많은 클래스에서 샘플을 삭제하는 방식입니다.
- 특징 학습(feature learning)에 중요한 데이터가 버려질 수 있다는 단점이 있습니다.
- Over-sampling은 과적합(overfitting) 위험이 크기 때문에 일구 연구에서는 데이터 손실이 있더라도 Under-sampling을 선호하기도 합니다.
- Over-sampling
- 샘플 데이터가 적은 클래스에 샘플을 추가하는 방식입니다.
- 중복된 샘플이 대량으로 추가되어 과적합(overfitting)의 위험이 있습니다.
- 인접 샘플을 보간(interpolation)하는등 새로운 샘플을 합성하는 방법에 대한 연구들이 진행되고 있습니다.
2. Cost-sensitive re-weighting
- 클래스 간 불균형(class imbalance)을 완화하기 위해 클래스 빈도(class frequency)에 따라 샘플 가중치(weight, $w_i$)를 주는 방식입니다.
- 손실 함수(loss)를 계산할 때, 각 샘플의 loss에 샘플 가중치($w_i$)를 곱합니다.
전통적인 방식(inverse frequency weighting)
\(w_i = \frac{1}{n_i}\)
- 샘플 빈도의 역수를 가중치로 하는 가장 간단한 방법입니다.
- 단순하지만, 대규모 실제(real-world) 긴꼬리(long-tailed) 데이터에서는 성능이 낮게 나타납니다.
- 희귀 클래스의 가중치가 지나치게 커져서 희귀 클래스를 과하게 학습하는 등 학습 불안정성이 있습니다.
개선된 방식(smoothed weight)
\(w_i = \frac{1}{\sqrt{n_i}}\)
- 희귀 클래스의 가중치가 지나치게 커지는 것을 완화한 방식입니다.
🔍 EXTRA
데이터 수와 상관없는 re-weighting Sample Difficulty로 기반한 re-weighting 방법도 존재합니다. s 학습하기 어려운 샘플(손실이 큰 샘플)에 더 높은 가중치룰 부여하는 방식으로, 노이즈 데이터나 잘못 라벨링된 데이터에도 높은 가중을 줄 수 있는 부작용이 있습니다.
3. 그 외
- 지식 전이(knowledge transfer)
- 다수 클래스(major class)에서 학습된 표현(feature representation)을 소수 클래스(minor class)에 전달하여 일반화 성능을 높이는 방식입니다.
- Metric Learning
- 각 클래스 간의 거리를 학습해 동일 클래스 샘플은 가깝게, 서로 다른 클래스 샘플은 멀게 임베딩 공간에서 배치함으로써 불균형 상황에서도 분류 경계를 명확히 하는 것을 목표로 하는 방식입니다.
Proposed Approach
문제 제기
- 실제 데이터는 대부분 long-tailed distribution 을 가지고 있습니다.
- 기존 해결책의 re-sampling은 정보 손실, overfitting의 위험성을 가지고 있으며, Inverse frequency weighting은 과도한 보정으로 학습 불안정하다는 단점이 있습니다.
- 따라서, Inverse frequency weighting이 아닌 안정적 가중치 적용 방법을 고안해야 합니다.
아이디어
- 일반적으로 생각했을 때, “데이터가 많을수록 좋다” 라고 생각할 수 있지만, 꼭 그런 것은 아니다.
- 데이터가 많아지면 데이터가 서로 배타적이고 다른 정보만 가지고 있을 확률이 줄어듭니다.
- 데이터 수 많아질수록 정보 중복(information overlap) 때문에 한계 효용(marginal benefits)이 점점 감소하게 됩니다.
- 따라서, 저자들은 단순한 샘플 수도 가중치를 주는 것이 아니라 한계 효용의 개념이 포함된 “유효 샘플 수(Effective number of samples)” 라는 개념을 도입합니다.
Effective Number of Samples의 이해
개념적인 접근
- Effective Number of samples를 도입하기 위해서 데이터 샘플링 과정을 Random Covering 으로 바라봅니다.
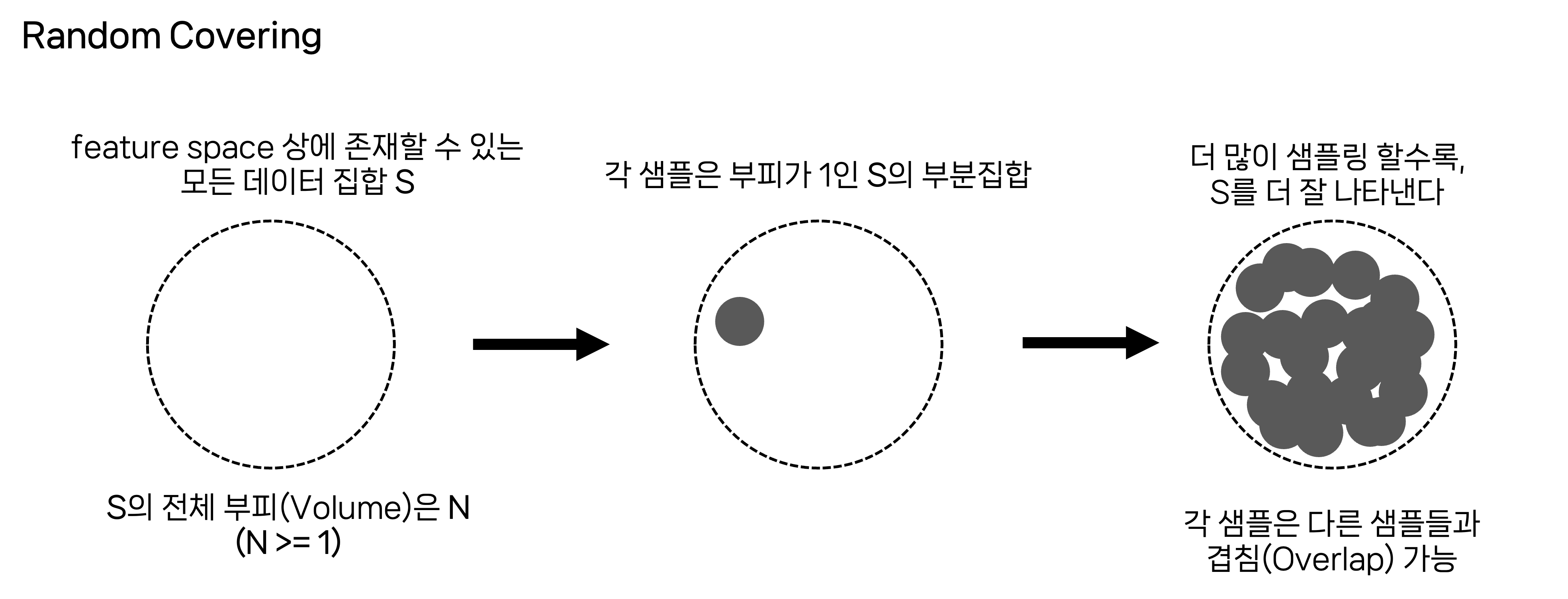
- feature space 전체를 S라 하고, S는 존재 가능한 모든 데이터의 정보 공간을 의미합니다.
- 각 샘플은 S안에서 부피가 1인 작은 부분 영역(subset)으로 표현할 수 있습니다.
- 새로운 샘플을 추가할 때마다 전체 공간S를 더 잘 덮게 되지만, 이미 덮인 영역과 겹칠 수도 있고(overlap), 완전히 새로운 영역을 덮을 수도 있습니다.
- 겹침이 많아질수록 새로 추가되는 샘플이 제공하는 새로운 정보량(new information)은 줄어듭니다.
- 따라서, 단순히 샘플의 개수 N이 많다고 해서 정보량이 선형적으로 증가하지 않습니다.
💡 정의
이 때, “유효 샘플 수(Effective number of Samples)“란,
실제로 중복을 제외한 순수한 정보량의 기댓값(기대 부피, Expected Volume)을 의미합니다.- 다시 말해, “서로 다른 영역을 덮는 정도”를 반영한 실질적인 샘플 수” 입니다.
수식적인 접근
전제
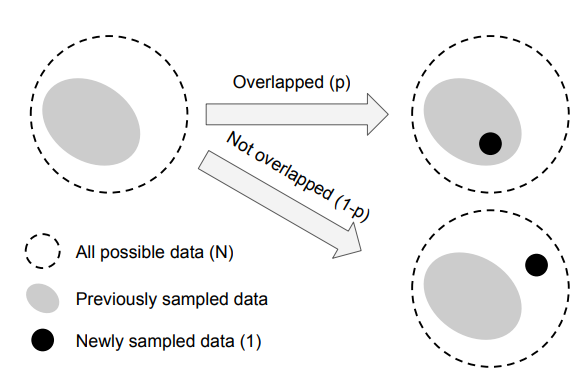
- 샘플들을 기대 부피(Expected volume)을 계산하는 것은 원래는 복잡하지만, 단순화하기 위해 새로 샘플링한 데이터 이전의 샘플된 영역을 부분적으로 덮는 경우는 고려하지 않습니다.
- 새로 샘플링한 데이터가 이전 샘플링된 영역 안에 완전히 포함될 확률: p
- 새로 샘플링한 데이터가 이전 샘플링된 영역 완전히 밖에 있을 확률: 1 - p
- 샘플 수가 늘어날수록 p(겹칠 확률)은 점점 증가합니다.
- 샘플들을 기대 부피(Expected volume)을 계산하는 것은 원래는 복잡하지만, 단순화하기 위해 새로 샘플링한 데이터 이전의 샘플된 영역을 부분적으로 덮는 경우는 고려하지 않습니다.
- 명제 (Proposition)
- 기대 부피(Expected Volume)를 $E_n$ (n은 실제 데이터의 수) 이라고 할 때,
- 증명
- 귀납법으로 증명합니다.
- n = 1인 경우, $E_1 = 1$
- n - 1 개의 샘플을 뽑은 상태에서 n번 째 샘플을 뽑는 상황을 가정하면, 이전에 샘플링된 데이터의 기대 부피는 $E_{n-1}$ 이고, 새로 뽑은 샘플이 기존 샘플의 영역과 겹칠 확률 p는 아래와 같습니다.
(전체크기 N에서 기존 샘플 영역이 차지하는 크기는 $E_{n-1}$ 이기 때문입니다.)
- n번째 샘플을 포함한 기대 부피 $E_n$은 다음과 같습니다.
\(E*n = pE*{n-1} + (1 - p)(E*{n-1} + 1) = 1 + \frac{N - 1}{N}E*{n-1} \quad (1)\)
- $ E{n-1} = \frac{1 - \beta^{n-1}}{1 - \beta} $ 을 만족한다고 하면, $ E{n-1} = \frac{1 - \beta^{n-1}}{1 - \beta} $ 을 (1)번식에 대입하면, $E_n$ 이 아래와 같이 정리되면서 귀납적으로 증명이 됩니다.
- 추가
- $E_n$ 을 자세히 보면, 고등학교 때 배웠던 등비수열의 합 공식과 같은 것을 볼 수 있습니다.
\(E*n = \frac{1 - \beta^n}{1 - \beta} = \sum*{j=1}^{n} \beta^{j-1} \quad (3)\)
- 등비수열의 관점에서 보면 n번째 샘플은 $\beta^{n-1}$ 만큼의 기여도를 가지는 것으로 볼 수 있습니다.
- 무한등비급수의 합 공식을 이용하면, 클래스 전체 데이터의 총 부피를 구할 수 있습니다.
\(N = \lim*{n \to \infty} \sum*{j=1}^{n} \beta^{j-1} = \frac{1}{1 - \beta} \quad (4)\)
- 앞서 정의한 $\beta = \frac{N - 1}{N}$ 과 일관되는 것을 확인할 수 있습니다.
결과 및 성질 (Asymptotic Properties, 점근적/극한적 성질)
\(E_n = 1 \text{ if } \beta = 0 \; (\text{즉, } N = 1), \quad E_n \to n \text{ as } \beta \to 1 \; (\text{즉, } N \to \infty)\)
- $\beta = 0 $ (N = 1) 이면, $E_n = 1$
- 모든 데이터가 사실상 “하나의 원형(prototype)“에서 파생한 것으로 볼 수 있습니다.
- 모든 샘플이 거의 동일하거나, 단순한 데이터 증강(augmentation)을 통해 만들어진 경우로 볼 수 있습니다.
- 유효 샘플 수 $E_n$ 이 항상 1로 유지됩니다.
- $\beta \rightarrow 1$ 로 갈수록
- 각 샘플이 서로 완전히 독립적이고 구별되는 정보를 가지는 것으로 볼 수 있습니다.
- 모든 샘플이 서로 다른 영역을 커버하게 되는 것이므로, 유효 샘플 수 $E_n$ 은 실제 샘플 수 n에 가까워집니다.
- 수학적 증명
- $\beta = 0 $ 이면, $E_n = 1$
- $\beta \rightarrow 1$ 일 때, $E_n$ 은 0 / 0 꼴 입니다. 이는 L’Hôpital’s Rule (로피탈의 정리) 적용해서 해결할 수 있습니다.
- $ f(\beta) = 1 - \beta^n, \quad g(\beta) = 1 - \beta $ 라 하면, 로피탈 정리를 이용하면 아래와 같이 정리할 수 있습니다.
- $\beta = 0 $ (N = 1) 이면, $E_n = 1$
Class-Balanced Loss
수식 정의 및 원리
- Class-Balanced Loss는 데이터 불균형(imbalanced data) 상황에서의 학습 문제를 해결하기 위해 고안된 손실 함수
클래스별 유효 샘플 수(Effective number of samples, $E_n$ )에 반비례하는 가중치$\alpha_{i}$ (weighting factor)를 손실 함수에 도입 ($\alpha_i \propto \frac{1}{E_{n_i}}$) \(E\_{n_i} = \frac{1 - \beta^{n_i}}{1 - \beta}, \quad \text{where } \beta = \frac{N - 1}{N}\) \[CB(p; y) = \alpha*i L(p; y) = \frac{1}{E*{n_y}} L(p; y) = \frac{1 - \beta}{1 - \beta^{n_y}} L(p; y)\]
$n_y$ 는 정답 클래스 $y$ 의 샘플 개수
입력 샘플 $x$ 의 레이블을 $y \in {1, 2, \dots, C}$ ($C$ 는 전체 클래스 수) 라 하고, 모델이 예측한 클래스별 확률을 \[p = [p_1, p_2, \dots, p_C]^T \quad $p_i \in [0, 1]$\]
로 표현하면, 각 샘플의 손실은 $L(p,y)$ 입니다.
- (2)번 식에 의해 클래스 $i$ 의 유효 샘플 개수는 다음과 같습니다.
하지만 실제로 각 클래스 데이터 특성을 모두 알기 어렵기 때문에, 모든 클래스가 동일한 $N_i = N$ 을 공유한다고 가정하여, $\beta_i = \beta = \frac{N - 1}{N}$ 로 단순화합니다.
β에 따른 Class-balanced term의 변화
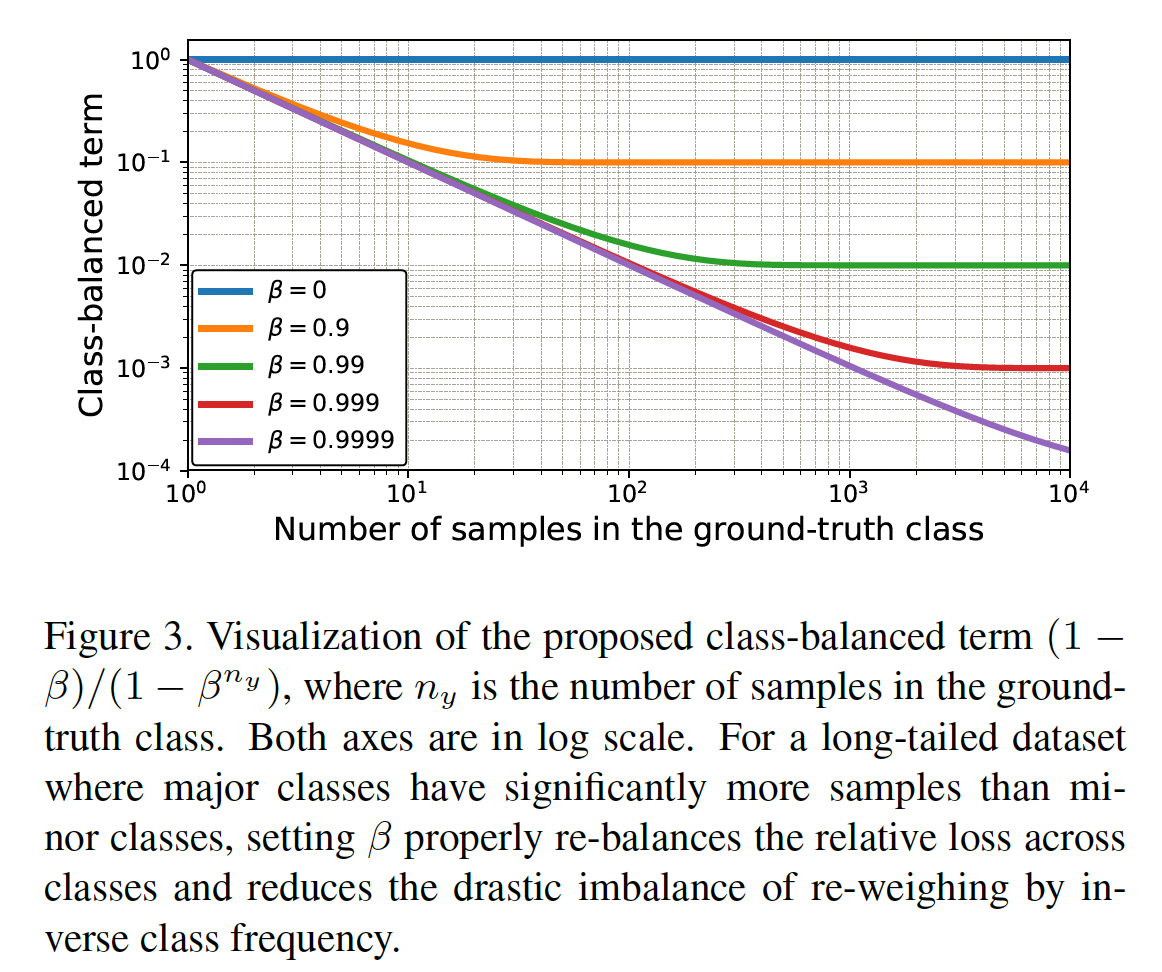
- $\beta = 0$ → 모든 클래스에 동일한 가중치 적용하게 됨으로써 모든 클래스가 동일한 비중으로 학습합니다. (no re-weighting)
- $ \beta \to 1$ → $\beta$ 가 1에 가까워질수록 각 클래스의 가중치는 클래스 빈도의 역수 ($\frac{1}{n_y}$) 형태로 수렴하게 됩니다.
- $\beta$ 가 1에 가까워질수록 데이터 작은 클래스일수록 더 큰 가중치를 받게 됩니다.
- 즉, $\beta$ 하나로 희귀 클래스의 영향력을 얼마나 키우고 줄일지 제어할 수 있습니다.
다양한 손실함수에서의 Class-balanced loss
- Class-balanced loss는 다양한 딥러닝 네트워크 구조나 여러 손실 함수(loss function)에 모두 적용 가능합니다.
Class-Balanced Softmax CrossEntropy Loss \(CB*{\text{softmax}}(z, y) = -\frac{1 - \beta}{1 - \beta^{n_y}} \log\left( \frac{\exp(z_y)}{\sum*{j=1}^{C} \exp(z_j)} \right) \quad (8)\)
Class-Balanced Sigmoid CrossEntropy Loss \(CB*{\text{sigmoid}}(z, y)= -\frac{1 - \beta}{1 - \beta^{n_y}} \sum*{i=1}^{C} \log\left( \frac{1}{1 + \exp(-z_i^t)} \right) \quad (11)\)
Class-Balanced Focal Loss \(CB*{\text{focal}}(z, y)= -\frac{1 - \beta}{1 - \beta^{n_y}} \sum*{i=1}^{C} (1 - p_i^t)^{\gamma} \log(p_i^t) \quad (13)\)
Experiments
개요
- Class-Balanced Loss 의 효과를 검증하기 위해 다양한 데이터셋에서 실험을 수행하였습니다.
- 먼저, 불균형 정도를 인위적으로 조절할 수 있는 Long-tailed CIFAR 데이터셋에서 데이터 불균형에 따른 성능 변화는 분석하였습니다.
- 또한, 실제(real-world) 불균형 데이터셋인 iNaturalist 2017과 iNaturalist 2018을 통해 현실적인 데이터에서도 일반화 성능을 평가하였습니다.
- 마지막으로 일반적인 시각 인식(visual recognition) 문제에 대한 적용 가능성을 확인하기 위해, ImageNet (ILSVRC 2022) 데이터셋에서도 추가 실험을 진행했습니다.
- 모든 실험에서는 ResNet 구조를 백본(Backbone)으로 사용하였습니다.
Datasets (데이터셋)
데이터셋의 불균형 계수 (Imbalance factor)
해당 논문에서는 데이터의 불균형 정도를 나타내는 불균형 계수(imbalance factor)를 사용하고 있으며, 다음과 같이 정의합니다. \[Imbalance Factor = \frac{가장 많은 샘플 수}{가장 적은 샘플 수}\]
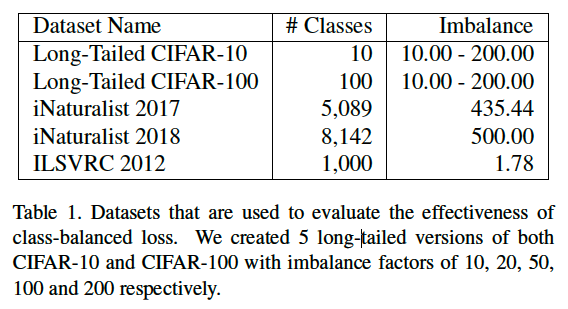
Long-tailed CIFAR
Long-tailed CIFAR는 각 클래스 $i$ 의 학습 샘플 수 $n_i$ 를 다음의 지수 함수(exponential function) 을 통해 감소시켜 데이터의 불균형 정도를 인위적으로 조절합니다.
\(n = n_i \cdot \gamma^i\)
- $i$ : 클래스 인덱스 (0부터 시작)
- $n_0$: 해당 클래스의 원래 학습 데이터 수
- $ \gamma \in (0, 1) $ : 불균형 조절 파라미터, 값이 작을수록 불균형이 심해짐 (Long-tailed 분포 강화)
- 해당 방식을 통해서 임의적으로 데이터의 클래스 인덱스가 증가할수록 데이티 수는 감소하는 형태로 데이터분포를 조정합니다.
- 해당 논문에서는 CIFAR-10, CIFAR-100을 불균형 계수 10 - 200 으로 조정해서 사용하였습니다.
iNaturalist
- 실제(real-world) long-tailed 이미지 데이터셋으로, 클래스 불균형이 매우 큰 것이 특징입니다.
- 2017: 5,089개 클래스, 579,184장의 학습 이미지
- 2018: 8,142개 클래스, 437,513장의 학습 이미지
ImageNet (ILSVRC 2012)
- 일반적인 시각 인식 (visual recognition) 성능 검증을 위해 사용하였습니다.
- 1,281,167장의 학습 이미지
- 50,000장의 검증 이미지
Results (결과)
Visual Recognition on Long-tailed CIFAR
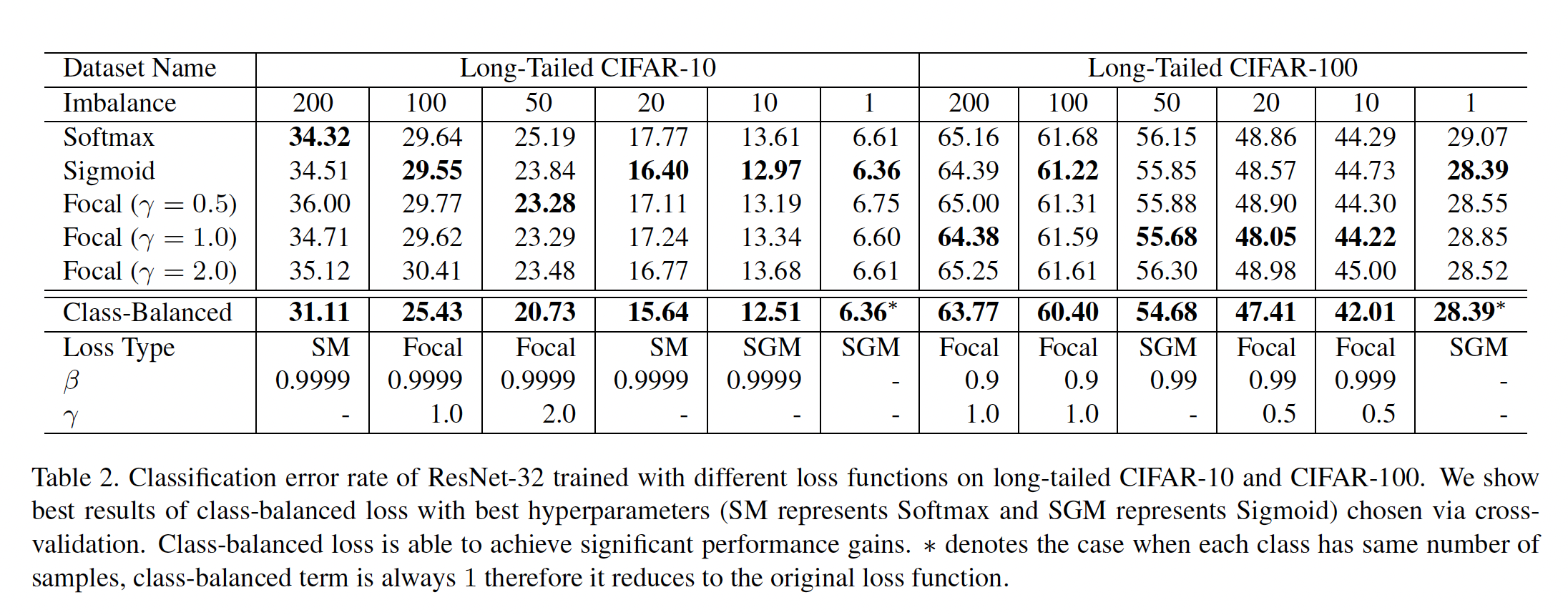
- 불균형 계수가 200, 100, 50, 20, 10, 1인 CIFAR-10과 CIFAR-100에 실험을 진행하였습니다.
- Table 2에는 Class-Balanced Loss를 적용하지 않은 Softmax, Sigmoid, Focal Loss를 적용했을 떄 Error Rate과, 다양한 하이퍼파라미터로 Class-Balanced Loss를 적용했을 때 Error rate과 그 때의 하이퍼파라미터가 나와있습니다.
- 실험 결과, 적절한 하이퍼파라미터(loss type, $\beta$ , $\gamma$)로 Class-Balanced Loss를 적용한 경우, 기존 손실 함수만 사용했을 때 보다 Error Rate가 전반적으로 낮아지는 것을 확인할 수 있습니다. (성능 향상)
- 특히, Class-balanced Loss를 Softmax보다 Sigmoid, Focal loss와 함께 사용했을 때 대부분의 경우 더 우수한 성능을 보였습니다.
- CIFAR-10에서는 $\beta = 0.999$ 로 일관적이지만, CIFAR-100에서는 불균형 계수에 따라 다양한 $\beta$ 값을 갖는 것을 확인할 수 있습니다.