Mixture-of-Agents Enhances Large Language Model Capabilities 논문 읽기
⚠️ 안내: 이 글은 학습 기록용입니다. 오류나 보완 의견은 댓글로 알려주세요.
수식이 제대로 표시되지 않는 경우는 랜더링 문제이니, 새로고침하면 해결됩니다.
1. Introduction
1.1 연구 배경
- 대형 언어 모델(LLM)은 자연어 이해 및 생성에서 뛰어난 성능과 성과를 보여왔음.
- 하지만, 이러한 모델들을 확장하고 발전시키는데 여전히 모델 크기와 학습 데이터의 한계를 가지고 있음
- 거의 비슷할 것이라고 생각하지만, 서로 다른 모델들은 각자의 고유한 강점을 가짐
- 예를 들어, A는 코드 생성을 잘하거나, B는 복잡한 지시를 잘 이행
→ 여러 모델들의 전문성을 결합해 더 강력하고 견고한 모델을 만들 수 있지 않을까?
1.2 LLM 이 가지는 특이한 특성
협동성(Collaborativeness)
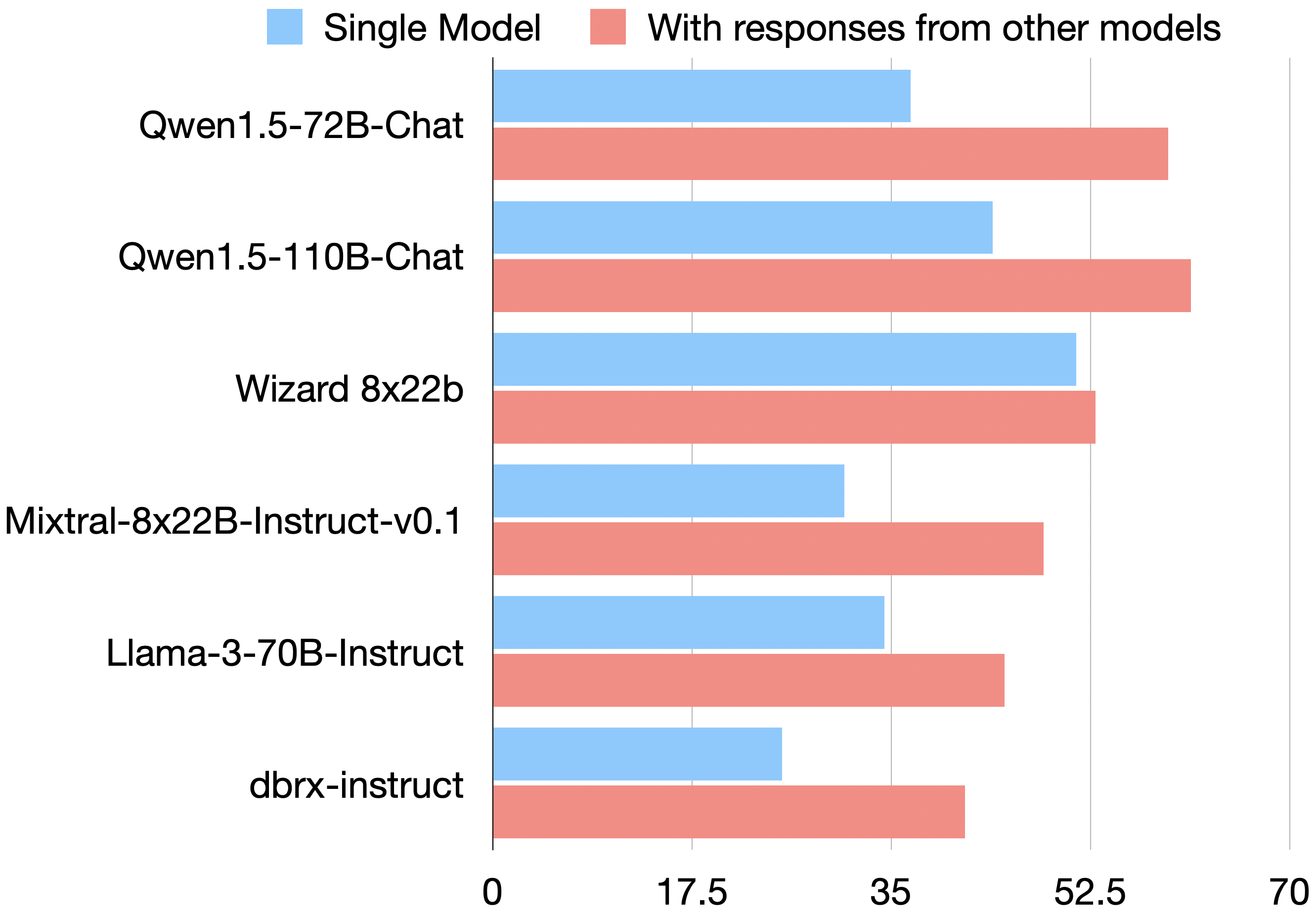
Figure 1: AlpacaEval 2.0 LC win rates improve when provided with responses from other models.
- 하나의 LLM이 다른 모델의 출력 결과를 함께 제공받을 때 더 나은 응답을 생성하는 경향
- 추가로 제공된 다른 모델의 출력 결과의 품질이 떨어져도 효과는 계속됨
2. Mixture-of-Agents (MoA)
2.1 협동성(Collaborativeness)의 최적화
- 여러 모델 간의 협동으로 부터 최대의 이익을 얻기 위해서 각 모델이 협업에서 어떤 역할을 잘 수행하는지 특성을 파악하는 것이 중요함.
- Proposers (제안자):
- 다른 모델이 참고할 수 있는 유용한 응답을 내는 데 능숙
- 좋은 proposer는 단독으로 높은 점수를 내지는 못하지만
- 다양한 맥락과 관점을 제공해줌으로써 최종 응답의 품질을 높이는데 기여
- Aggregators (통합자)
- 여러 모델의 응답을 하나의 고품질 응답으로 통합(synthesize) 하는 데 능숙한 모델
- 좋은 aggregator는 품질이 낮은 입력이 주어지더라도 이를 잘 융합해서 전체적인 출력 품질을 올림
- Proposers (제안자):
예를 들어, GPT-4o, Qwen1.5, LLaMA-3는 제안과 통합 모두에서 우수한 성능을 보인 반면, WizardLM은 제안자(proposer)로서는 매우 뛰어나지만, 다른 모델의 출력을 통합할 때는 성능이 저하되는 경향을 보였다.
2.2 Mixture-of-Agents 의 구조
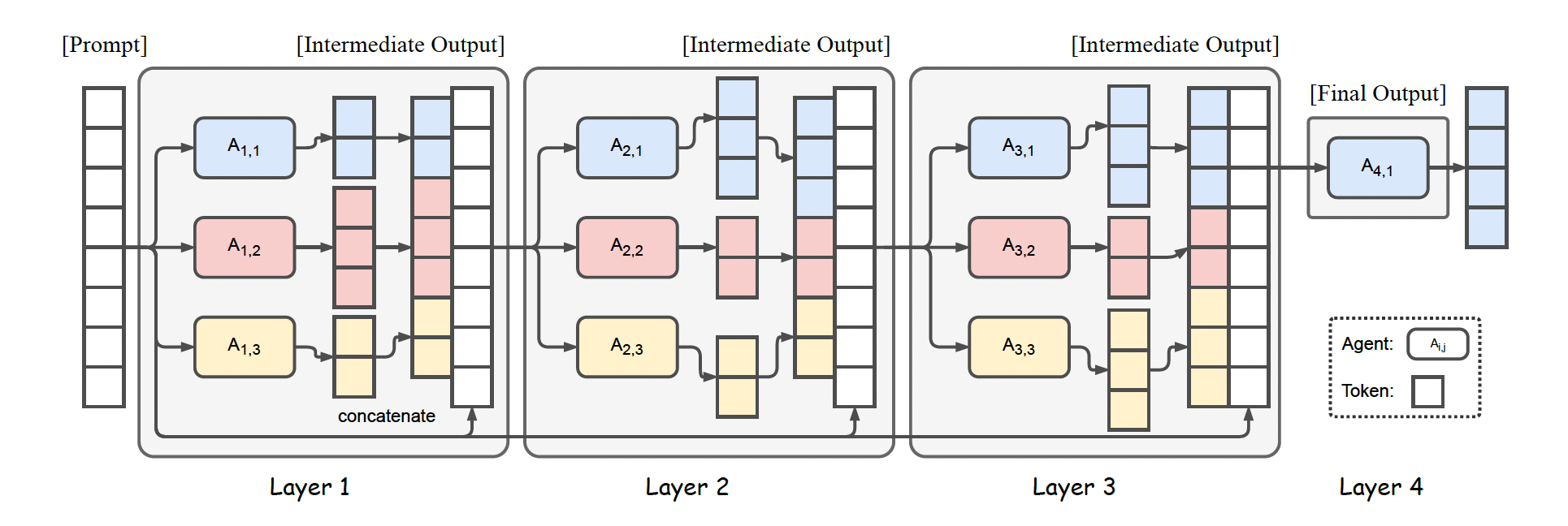
Figure 2: Illustration of the Mixture-of-Agents Structure. This example showcases 4 MoA layers with 3 agents in each layer.
- 모델은 총 I 개의 층(layer)로 구성되어 있으며, 각 i번째 층은 n의 LLM으로 이루어져있음.
- $A_{i,n}$ 으로 표기
- 여러 통합자 (aggregator)를 계속 도입해서 응답들을 재통합(re-aggregation)하는 구조로 이루어짐
- Layer 1는 Proposer Layer, 나머지 layer 2, 3, 4 는 Aggregation Layer 로 이전 레이어에서 온 응답들을 받아서 통합하는 구조
- LLM은 같은 층 내에서 또는 서로 다른 층 간에 또 사용할 수 있음. (reuse)
- 이는 하나의 모델이 확률적 샘플링(temperature sampling)에 따라 여러 다양한 출력을 생성하는 구조
- single-proposer (단일 제안자) 형태
- 추가 학습(fine-tuning) 하지 않고, 프롬프트 기반 생성 인터페이스만 활용
- 입력 프롬프트 $x_1$이 주어졌을 때, i번째 MoA 층의 출력 $y_i$는 다음과 같이 정의
- 여기서 “+”는 텍스트의 단순 연결(concatenation)
- “⊕” 는 Table 1 에 있는 Aggregate-and-Synthesize 프롬프트를 적용하여 통합하는 연산

Table 1: Aggregate-and-Synthesize Prompt
당신은 여러 오픈소스 모델들이 동일한 사용자 요청에 대해 생성한 응답들을 전달받았습니다.
당신의 임무는 이 응답들을 비판적으로 평가하고, 편향되거나 부정확한 정보가 있을 수 있음을 인식하면서,
정확하고 포괄적이며 고품질의 하나의 응답으로 통합(synthesize) 하는 것입니다.
단순히 주어진 답변을 복사하지 말고, 가장 신뢰할 수 있고 일관된 답변을 생성해야 합니다.
결과는 구조적이고, 명확하며, 정확해야 합니다.
모델들로 부터 받은 응답들:
1. [A_i,1 로 부터 받은 응답]
2. [A_i,2 로 부터 받은 응답]
...
n. [A_i,n 로 부터 받은 응답]
2.3 Mixture-of-Experts와의 비교
- Mixture-of-Experts (MoE)는 여러 “전문가 네트워크” 가 각기 다른 능력에 특화되어 협력하는 고전적이고 강력한 머신러닝 접근법
- MoE는 아래와 같은 형태로 표현됨
- 여기서 $E_{i,j}$는 j번째 전문가 네트워크
- $G_{i, j}$ 는 해당 전문가를 선택・조절하는 게이팅 네트워크(Gating Network)
- MoA는 MoE의 개념을 “모델 수준(Model level)”로 확장한 것
- MoE는 대형 모델 내부의 하위 네트워크를 활용하는 반면, MoA는 완전한 LLM들을 독립적인 에이전트로 활용하도록 설계한 것
- 프롬프트 수준에서 작동하는 Mixture-of-Experts
2.4 Mixture-of-Agents 의 장점
- 학습 불필요
- MoA는 사전 학습된 LLM을 그대로 사용하며, 파인튜닝 비용이 전혀 없음
- 프롬프트 기반 생성 인터페이스
- 유연성과 확장성
- 모델 크기나 아키텍처에 관계없이, 최신 LLM에 즉시 적용 가능
3. Evaluation
3.1 요약
- AlpacaEval 2.0, MT-Bench, FLASK 모두에서 MoA가 크게 향상된 성능을 보임. 특히, 오픈소스 모델만 사용한 경우에서 GPT-4o를 능가
- MoA 내부 메커니즘을 정량적으로 분석하여 왜 작동하는 지 설명
- 예산 및 토큰 분석을 통해 GPT-4 Turbo와 동등한 성능을 내면서 비용은 절반 수준임을 보임
3.2 Setup
Benchmarks (평가 지표)
- AlpacaEval 2.0: LLM이 인간 선호도에 얼마나 잘 부합하는지를 측정하는 대표적인 기준. 각 모델의 응답을 GPT-4 의 답변과 비교하고, GPT-4 기반의 평가자가 어느쪽을 선호하는지 판단
- MT-Bench: 멀티 턴(Multi-Turn) 대화 능력을 측정하는 벤치마크. 평가자는 GPT-4 이고 각 모델의 응답을 점수화(0 ~ 10점)
- FLASK: Functional LLM Ability Scorecard. 12가지의 세부 기준으로 모델을 기능적 성능을 평가
Models (사용모델)
- 기본 MoA는 모두 오픈소스 LLM으로 구성 (Qwen1.5-110B-Chat, Qwen1.5-72B-Chat, WizardLM-8x22B, LLaMA-3-70B-Instruct, Mixtral-8x22B-v0.1, dbrx-instruct)
- 기본 MoA는 3개의 층으로 구성하였고, 모든 층에서 동일한 모델 세트를 사용
- 마지막 통합자(aggregator)는 ‘Qwen1.5-110B-Chat’ 모델을 사용
- 추가 변형 모델
- MoA w/ GPT-4o: 최종 통합자만 GPT-4o로 바꾼 고품질 버전.
- MoA-Lite: 층을 2개로 줄이고 통합자를 Qwen1.5-72B-Chat으로 바꾼 비용 효율형 버전.
3.3 Benchmarks Results
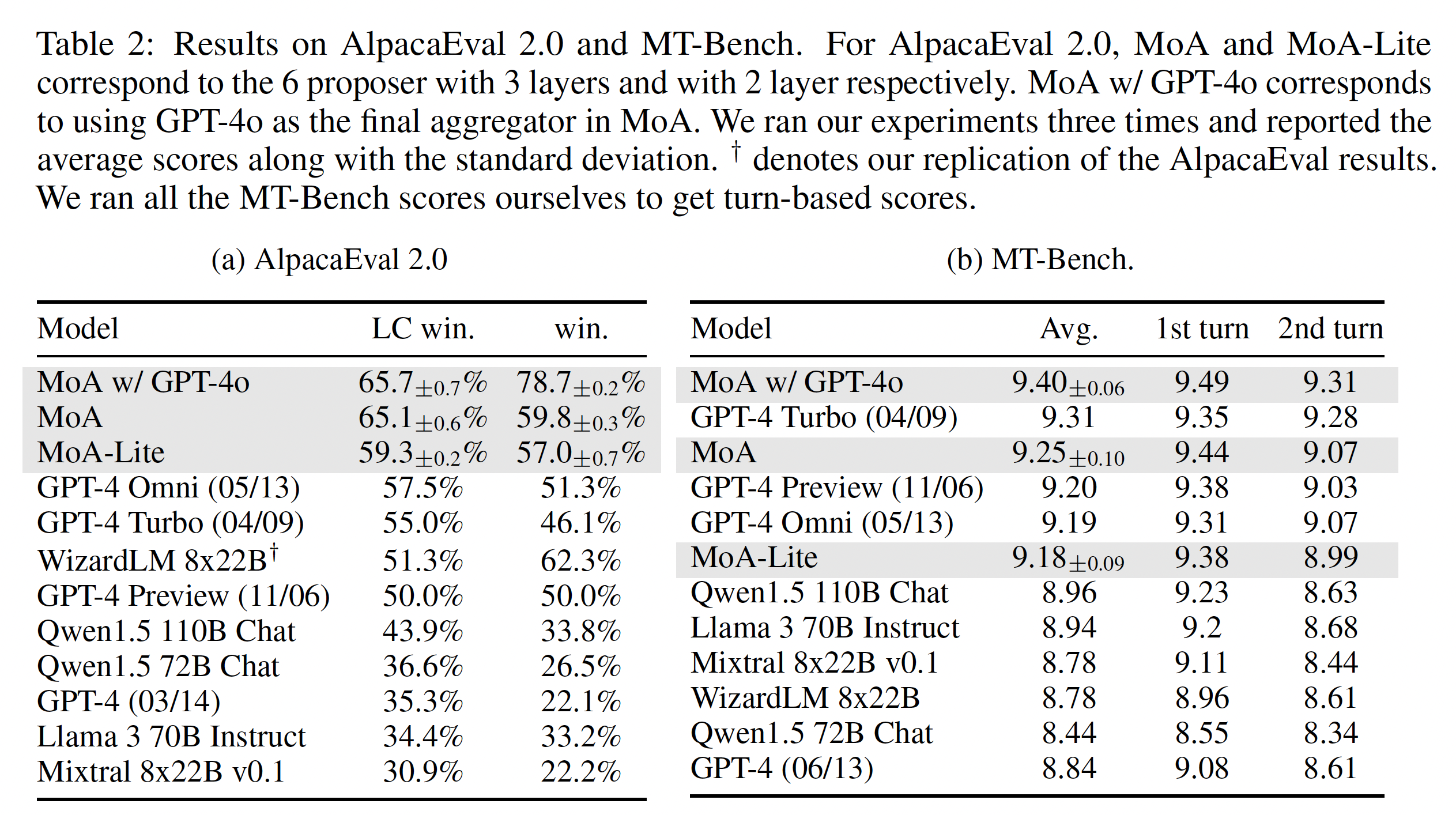
Table 2: Benchmark Results
- AlpacaEval 2.0
- MoA가 리더보드 최상위 차지, 이전의 최고 모델인 GPT-4o보다 +8.2%p 높은 LC 승률
- 오픈소스 모델만 사용한 MoA가 GPT-4o보다 +7.6%p 높은 LC 승률
- MoA-Lite 버전도 GPT-4o보다 +1.8%p 상회
- MT-Bench
- 기존 모델들이 이미 9점대에 근접해서 상승폭이 크지는 않았음
- 그래도 MoA가 리더보드 정상을 기록
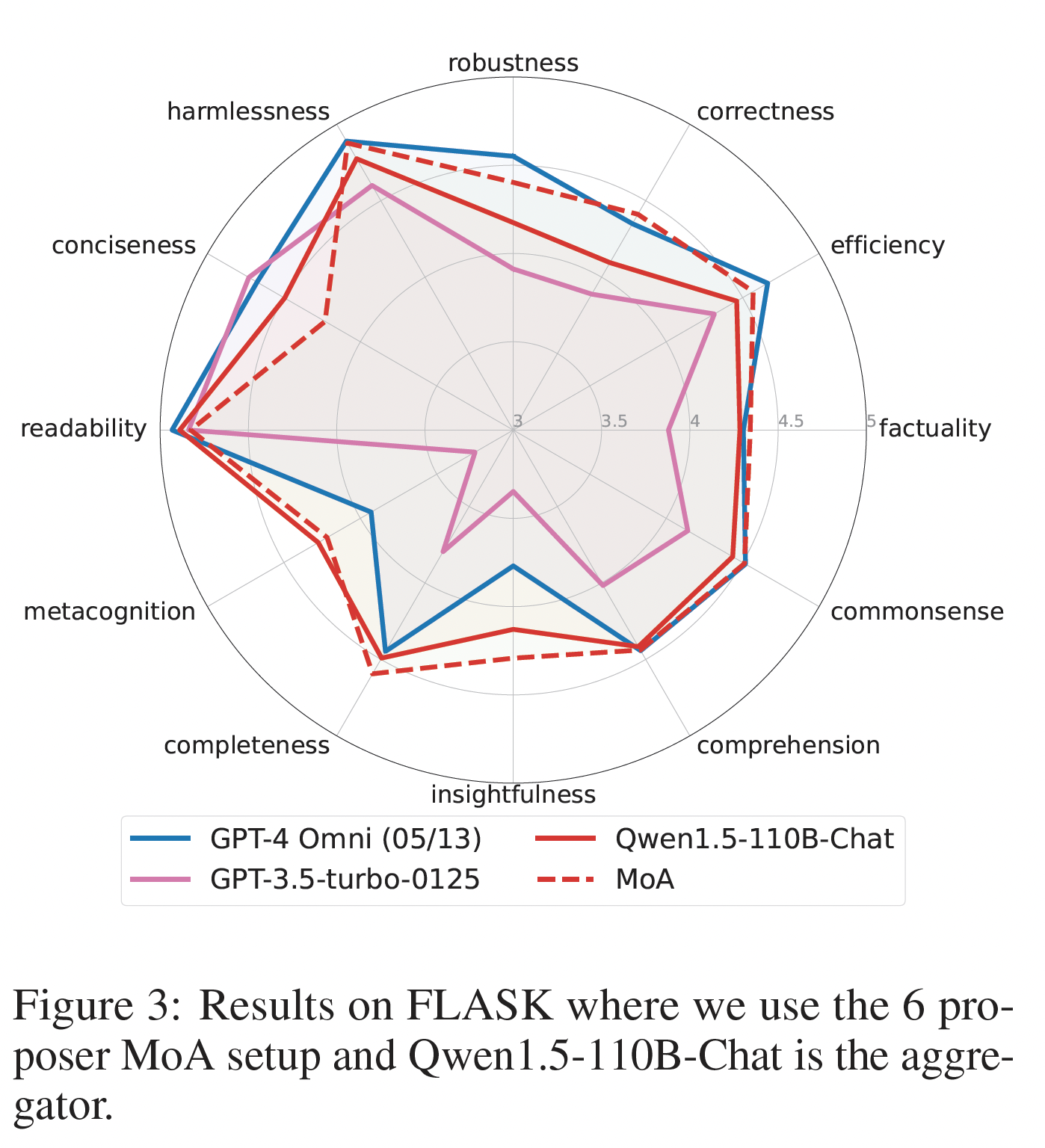
Figure 3: FLASK Results
- FLASK
- MoA는 robustness(견고성), correctness(정확성), efficiency(효율성), factuality(사실성), commonsense(상식성), insightfulness(통찰력), completeness(완결성) 에서 뚜렷한 향상을 보임
- GPT-4o 보다 correctness(정확성), factuality(사실성), insightfulness(통찰력), metacognition(메타인지) 에서 우수함
- conciseness(간결성)에서는 떨어짐
3.4 MoA가 잘 동작하는 이유? (What Makes MoA Work Well?)
- LLM-Ranker 보다 우월한 결과 (Figure 4-(a))
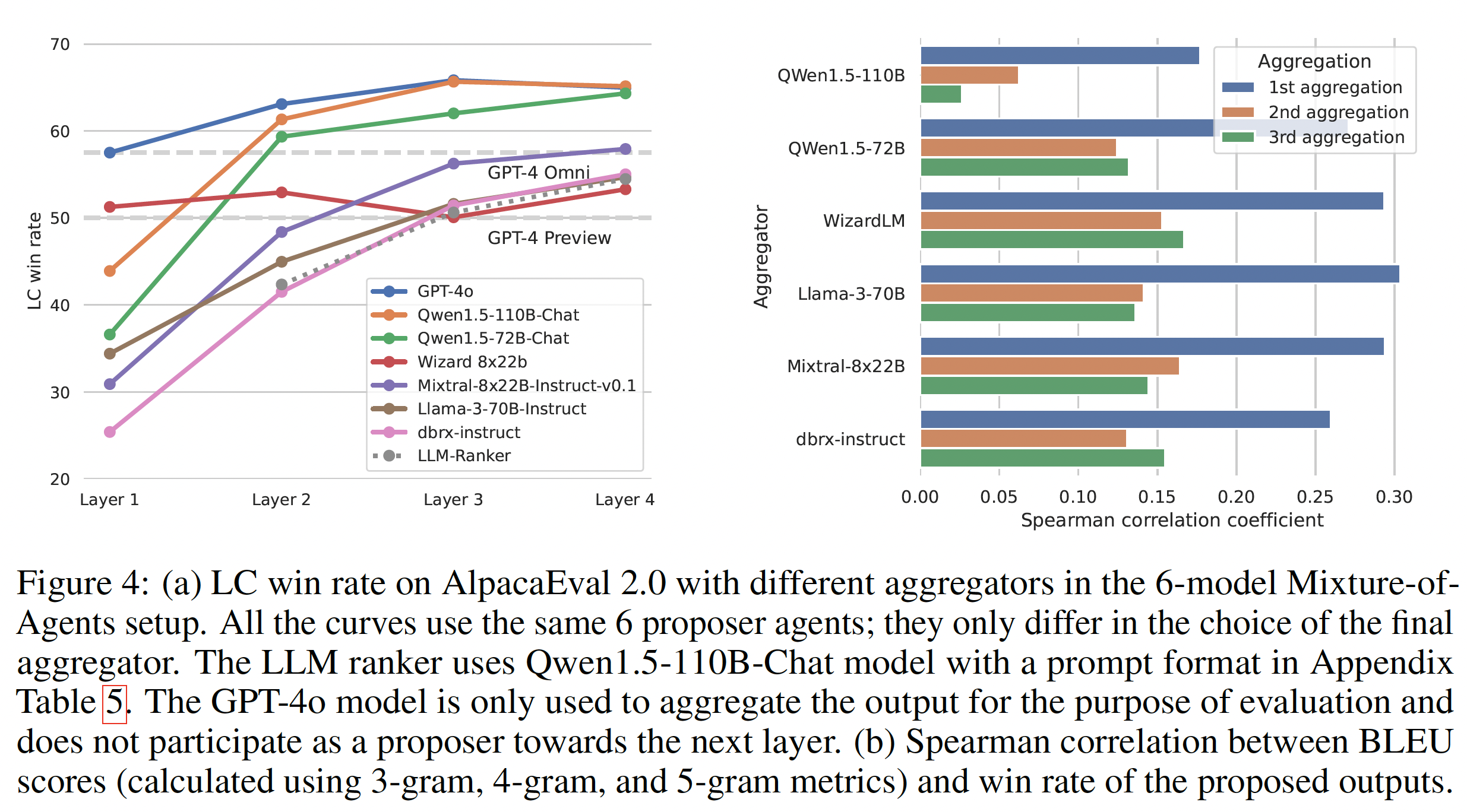
Figure 4: Analysis of MoA
- 여러 LLM 모델의 답변 중 가장 좋은 답변을 고르는 LLM-Ranker 방식과 비교했을 때, MoA가 우수한 성능을 보였음 → 이는 통합자가 단순 선택이 아니라 다양한 응답을 잘 합치고 다듬는 것을 의미함
- 최적 응답을 적극 반영 (Figure 4-(b))
- Figure 4-(b)는 BLEU 점수랑 Spearman 상관계수의 관계를 보여줌
- BLEU는 Aggregator가 proposer들이 낸 문장을 얼마나 많이 참고했는지를 보여주는 유사도(similarity) 점수
- Spearman correlation coefficient는 “유사도 순위”랑 “GPT-4 기반의 human preference 순위”의 일치 정도
- +1 에 가까울수록, 두 순위가 일치하는 것으로 (좋은 답변일수록 유사도가 높음)
- 0: 무관함
- -1 에 가까울수록, 반대 관계 (나쁜 답변일수록 유사도가 높음)
- 1차 aggregator들이 상관이 높게 나옴
- 1차 aggregator들이 proposer 층이 만든 응답을 직접 받아들이고, 좋은 proposer의 내용일 수록 반영이 많이 되기 때문에 값이 높게 나옴
- 2, 3차는 이미 통합된 내용을 다시 확인하면 중복제거, 요약, 재구성을 하기 때문에 양의 상관관계를 가지지만 크지는 않음.
- Figure 4-(b)는 BLEU 점수랑 Spearman 상관계수의 관계를 보여줌
→ MoA의 aggregator는 무작위로 답변을 섞는 게 아니라, 여러 제안 중 사람이 선호할 만한 좋은 답변의 특징을 잘 가져온다.
- 모델 다양성과 proposer(제안자 수)의 영향력
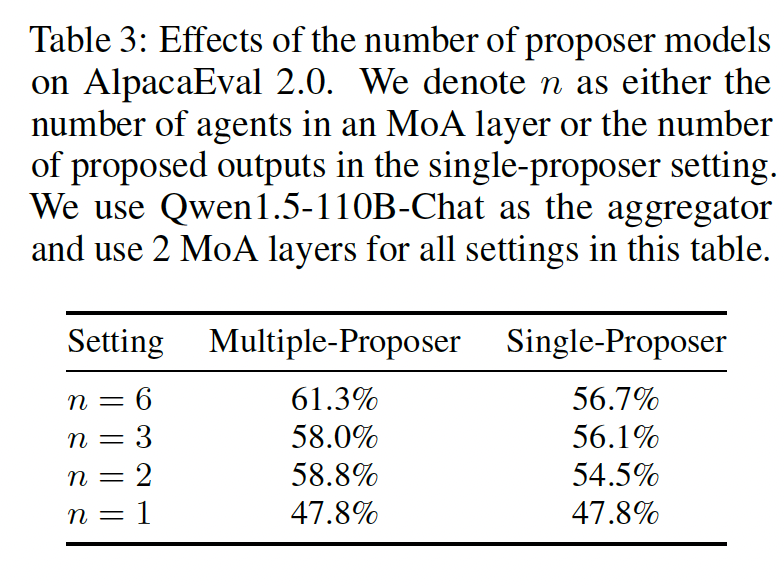
Table 3: Model Diversity and Number of Proposers
- Proposer(제안자) 수가 증가할수록 성능 향상
- 같은 모델을 여러번 샘플링한 Single-Proposer보다 서로 다른 LLM 모델을 사용하는 Multiple-Proposer가 성능이 더 좋음 → 다양한 LLM 조합의 MoA 구조가 성능 향상에 핵심
- 역할 전문화(Specialization)
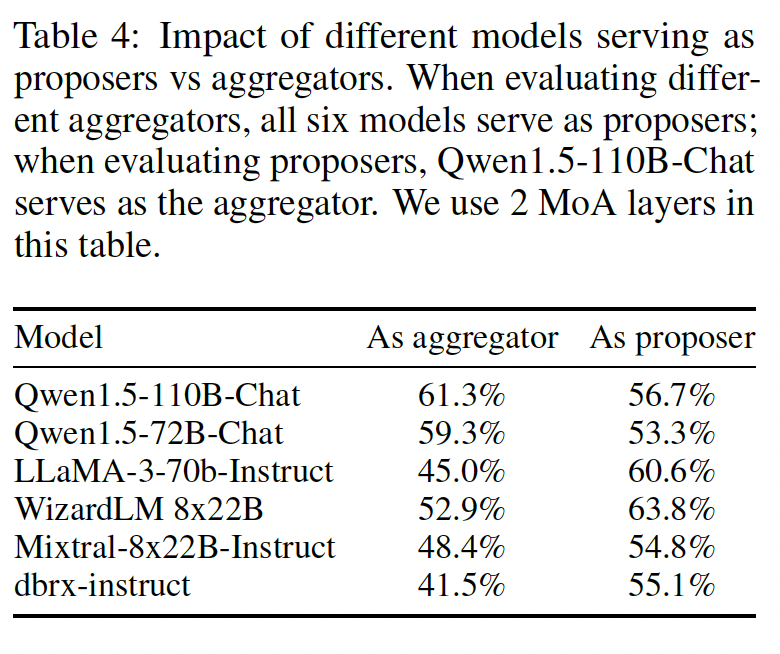
Table 4: Role Specialization
- GPT-4o, Qwen, LLaMA-3는 통합자와 제안자 양쪽 역할에 모두 강했음
- WizardLM은 Proposer에서 강세를 보임 → 각각의 LLM들이 서로 보완적인 전문성을 가짐
3.5 예산 및 토큰 분석
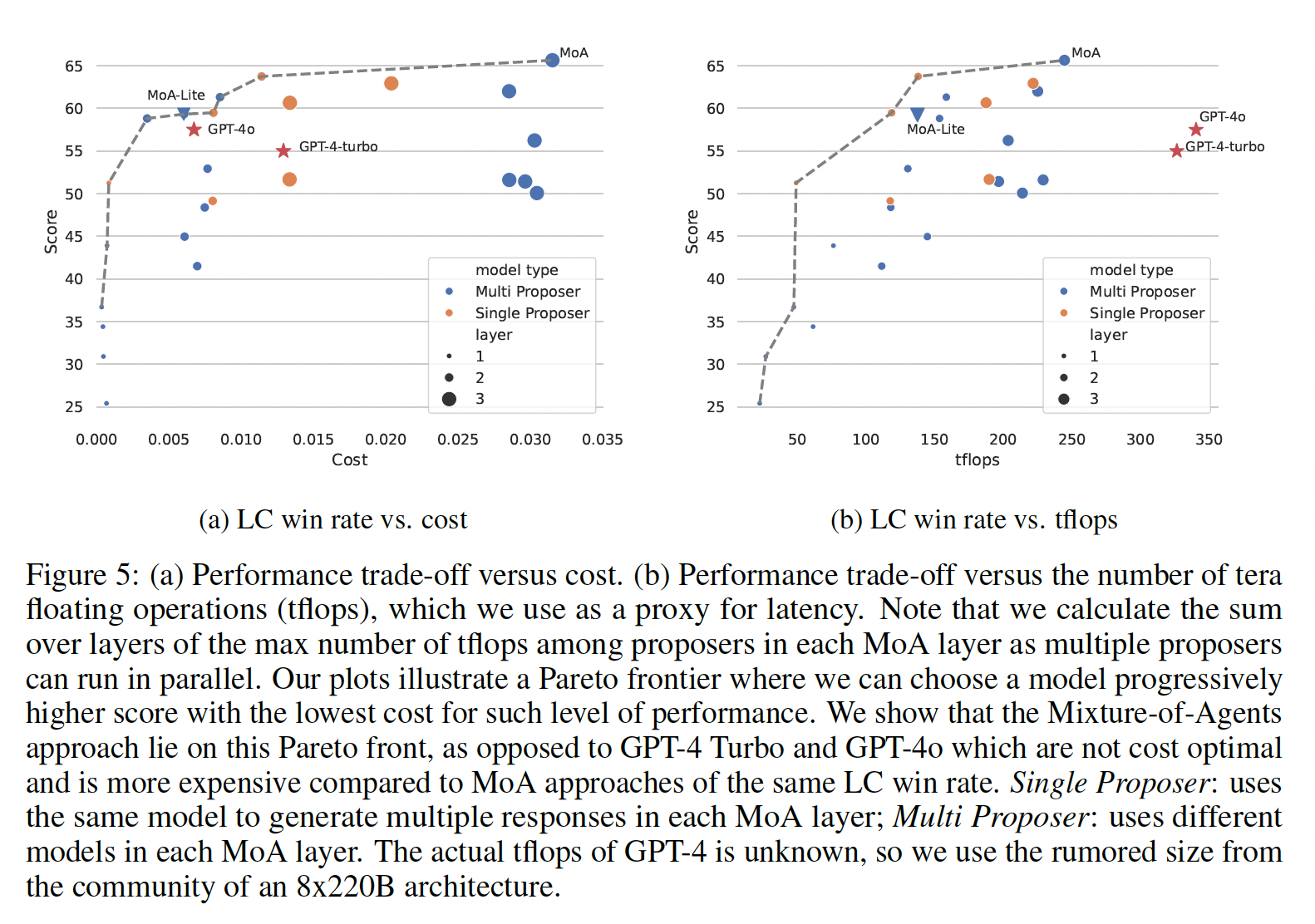
Figure 5: Budget and Token Analysis
- Pareto frontier(파레토 전선)
- 서로 다른 두 지표 사이의 최적의 균형점들의 집합
- 파레토 전선 아래 공간에 위치하면 비효율적
- 성능-비용(Figure 5-(a))
- MoA-Lite 와 MoA는 Pareto frontier 위에 위치 (고성능, 저비용)
- MoA-Lite 는 GPT-4o와 유사한 비용으로 약 4 % 높은 성능을 보임 → 따라서 MoA 계열이 성능-비용 균형 (Pareto Optimal) 을 이룸
- 성능-연산량(Figure 5-(b))
- TFLOPs (Tera Floating-Point Operations per Second): 초당 1조 번의 부동소수점 연산의 단위. 한 번의 추론을 할 때 필요한 계산량
- MoA는 Pareto frontier에 위치하고, MoA-lite 는 Pareto frontier에 근접 → MoA 및 MoA-Lite 가 GPT-4 Turbo · GPT-4o 보다 앞선 효율을 보임
Conclusion
- Mixture-of-Agents는 여러 LLM 간 협동적 추론(collaborative reasoning) 을 공식화한 새로운 프레임워크
- 추가 학습(fine-tuning) 없이 프롬프트 기반으로 작동
- 모델 확장과 조합이 용이하며 비용 효율성 + 성능 모두 확보
- 다양한 도메인(코드, 대화, 추론, 평가 등)에 손쉽게 적용 가능